
Everyone obsesses over benchmark scores. But there's a more fundamental question: does the model tell the truth? We pulled the latest hallucination data from Vectara's HHEM benchmark and Artificial Analysis to create the most comprehensive honesty ranking of frontier AI models in 2026. Some findings defy conventional wisdom — smaller models often lie less, and adding "reasoning" paradoxically doubles or triples hallucination rates. Test these models yourself on CodingFleet's AI Chat or use our Code Assistant to catch bugs.
📊 Key Findings
- Claude Fable 5 debuts at #1 on AA-Omniscience (40) with 61% accuracy — but its score is accuracy-driven, not low-hallucination driven. A strategic shift for Anthropic.
- GPT-5.4 Mini (5.5%) and GPT-5.5 (9.3%) lead the Vectara HHEM hallucination rankings among the current-gen capable models tested
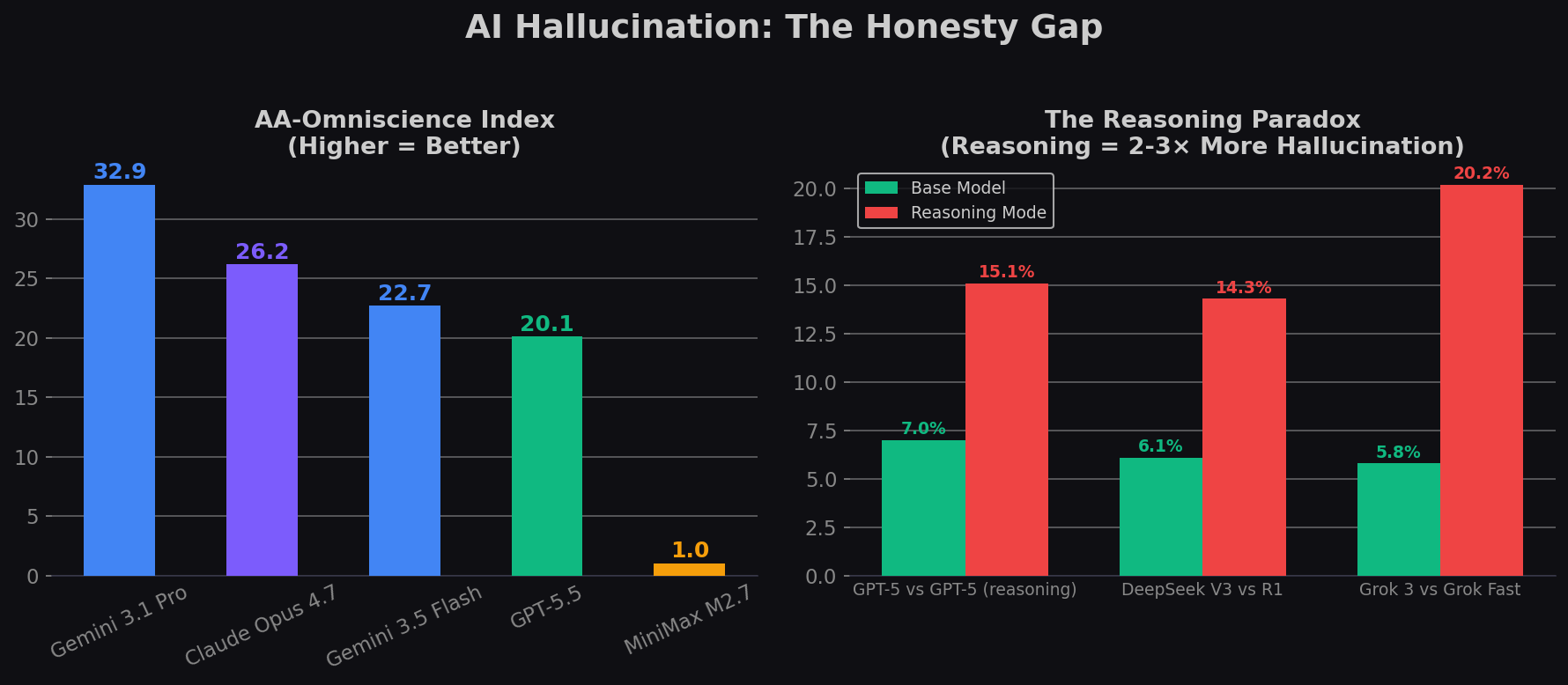
- Gemini 3.1 Pro previously topped AA-Omniscience at 32.9 — Fable 5 beats it by 7 points, but Gemini still excels at admitting ignorance over fabricating
- The Reasoning Tax is real: thinking/reasoning modes amplify hallucination 2–3× across all model families
- Claude Opus 4.8 takes the classic Anthropic trade: lower Vectara rate but AA-Omniscience Index of 27.4 (third overall) with 35.9% hallucination — calibrated honesty at moderate accuracy
- Qwen 3.7 Max debuts at 22.9% AA-Omniscience hallucination rate — the best calibration of any non-Anthropic model at scale
- Fable 5 changes the Claude playbook: for the first time, Anthropic ships a model that prioritizes raw accuracy over calibrated refusal — 61% accuracy (beating GPT-5.5's 57%) with a higher hallucination rate than Opus 4.8
Want to experiment with these models yourself? All ranked models are available on CodingFleet. Start a new chat →
⚠️ Why Small Models Are Not Included
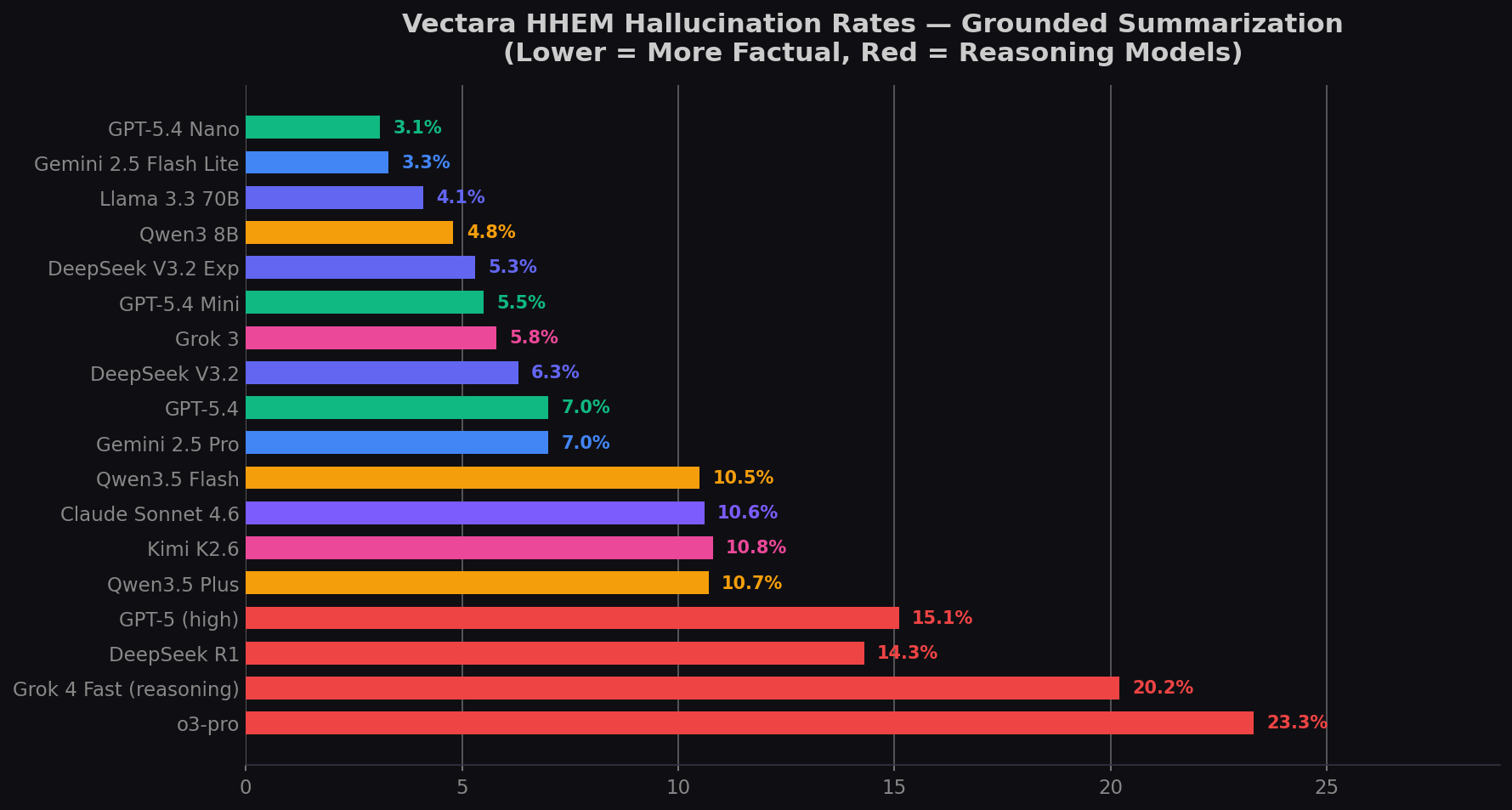
This analysis focuses on capable general-purpose models suitable for professional software development and knowledge work. Models like GPT-5.4 Nano (3.1% Vectara), Qwen3 8B (4.8%), and Gemini 2.5 Flash Lite (3.3%) score impressively low hallucination rates — but they are not general-purpose coding or reasoning models. Including them would be misleading: a model that can barely code will naturally hallucinate less because it's not attempting complex tasks in the first place. These small models are excellent for narrow summarization pipelines but are not competitors to the frontier models analyzed here. The benchmark data confirms this: GPT-5.4 Nano scores far below frontier models on SWE-bench Pro and is not suitable for agentic coding. Lower hallucination ≠ better model.
What These Benchmarks Actually Test
There are two fundamentally different ways to measure hallucination, and they often disagree. Understanding the difference is essential to reading any honesty ranking:
| Benchmark | What It Measures | Good Score | Risk |
|---|---|---|---|
| Vectara HHEM | How often a model invents facts when summarizing a document. Tests grounding to source material. | Lower is better <5% excellent, >10% concerning |
Models can "game" this by refusing to summarize — answer rate must be checked |
| AA-Omniscience | Whether a model admits ignorance when it doesn't know an answer. 6,000 questions across 42 topics. | Higher Index is better >10 good, >25 excellent |
Models with very low scores either fabricate aggressively or refuse too much |
The key insight: Vectara tests "does it stick to the source?" while AA-Omniscience tests "does it know what it doesn't know?" A model can ace one and fail the other. Claude Opus 4.7 is the clearest example: 12.0% Vectara (concerning) but 26.2 AA-Omniscience Index (excellent). It fabricates more in summarization than most peers, but it's one of the best at saying "I'm not sure" when it genuinely lacks knowledge.
Vectara HHEM: The Summarization Truthfulness Ranking
Vectara's Hughes Hallucination Evaluation Model (HHEM) is the industry standard for factual grounding. The benchmark evaluates models on 7,700+ documents spanning law, medicine, finance, and education — summarization tasks where source fidelity is critical. All scores below are from the new (tougher) dataset where answer rate ≥ 95%. Small models (GPT-5.4 Nano, Qwen3 8B, Gemini Flash Lite) excluded as they are not general-purpose coding/reasoning models.
| Model | Provider | Vectara HHEM | Fact. Consistency | Tier |
|---|---|---|---|---|
| GPT-5.4 Mini | OpenAI | 5.5% | 94.5% | ✅ Excellent |
| DeepSeek V4 Pro | DeepSeek | 8.6% | 91.4% | ✅ Good |
| MiniMax M2.7 | MiniMax | ~9.1%* | ~90.9% | ✅ Good |
| GPT-5.5 | OpenAI | 9.3% | 90.7% | ✅ Good |
| Claude Haiku 4.5 | Anthropic | 9.8% | 90.2% | ⚠️ Borderline |
| GLM-5* | zAI | 10.1% | 89.9% | ⚠️ Borderline |
| Gemini 3.1 Pro | 10.4% | 89.6% | ⚠️ Borderline | |
| Qwen 3.6 Flash** | Alibaba | 10.5% | 89.5% | ⚠️ Borderline |
| Claude Sonnet 4.6 | Anthropic | 10.6% | 89.4% | ⚠️ Borderline |
| Kimi K2.6 | Moonshot | 10.8% | 89.2% | ⚠️ Borderline |
| Claude Opus 4.7 | Anthropic | 12.0% | 88.0% | 🔴 Concerning |
* MiniMax M2.7 not yet on Vectara; M2.5 predecessor score (9.1%) shown as estimate. ** Qwen 3.5 Flash score shown; Qwen 3.6 Flash not yet independently verified. GLM-5 score shown; GLM-5.1 not yet on Vectara. Source: Vectara HHEM Leaderboard, last updated May 11, 2026.
Still not on Vectara's new dataset (as of May 31, 2026): Claude Opus 4.8, Grok 4.3, Grok 4.1 Fast, Gemini 3.5 Flash, Gemini 3 Flash, DeepSeek V4 Flash, GPT-5.4 (standard), Qwen 3.7 Max, Qwen 3.6 Plus, GLM-5.1, GLM-5V Turbo. These are all very recent releases (April–May 2026) and Vectara typically adds models ~4–8 weeks after launch.
The Reasoning Paradox: Smarter Models Lie More
This is the most counterintuitive finding in the data. Models in "reasoning mode" — which spend extra tokens thinking through a problem — consistently hallucinate 2–3× more than their base counterparts:
| Model Pair | Base Hallucination | Reasoning Mode | Increase |
|---|---|---|---|
| GPT-5.4 → GPT-5 (high reasoning) | ~7% | >10% | ~1.5× |
| DeepSeek V3.2 → R1 | 5.3% | 11.3% | 2.1× |
| Grok 3 → Grok 4 Fast (reasoning) | 5.8% | 20.2% | 3.5× |
Why does this happen? The leading hypothesis is that reasoning models "over-think" — they generate lengthy internal chains that drift from source material. More thinking = more opportunities to invent plausible-sounding but wrong details. This has real implications: for summarization and fact-grounded tasks, use base (non-reasoning) models. Reserve reasoning mode for math, coding, and logic puzzles where fabrication risk is lower.
AA-Omniscience Index: A Different Measurement
Artificial Analysis measures hallucination differently — their Omniscience Index evaluates how often a model correctly admits it doesn't know a fact (as opposed to fabricating). Higher is better. It's a complementary signal:
| Model | Provider | AA-Omniscience Index | Accuracy | Halluc. Rate |
|---|---|---|---|---|
| 🆕 Claude Fable 5 (Adaptive, Max Effort) | Anthropic | 40.0 | 61.0% | Higher* |
| Gemini 3.1 Pro | 32.9 | 55.3% | 50% | |
| Claude Opus 4.8 (Adaptive, Max Effort) | Anthropic | 27.4 | 46.6% | 35.9% |
| Claude Opus 4.7 (Adaptive) | Anthropic | 26.2 | ~47% | 36% |
| Gemini 3.5 Flash | 22.7 | N/A | N/A | |
| GPT-5.5 (xhigh) | OpenAI | 20.1 | 57% | 86% |
| Grok 4.3 | xAI | 18.3 | N/A | N/A |
| Gemini 3 Pro | 15.8 | N/A | N/A | |
| Qwen 3.7 Max | Alibaba | 14.1 | N/A | 22.9% |
| GPT-5.4 | OpenAI | 5.7 | N/A | N/A |
| Kimi K2.6 | Moonshot | 6.4 | N/A | N/A |
| MiMo V2.5 Pro | Xiaomi | 3.6 | N/A | 24.5% |
| Qwen 3.6 Plus | Alibaba | 2.7 | N/A | N/A |
Source: Artificial Analysis — AA-Omniscience, June 10, 2026. Hallucination rates from Suprmind compilation. *Fable 5's exact hallucination rate not published — AA states its Index score is "driven by leading accuracy, rather than low hallucinations." Its hallucination rate is higher than Opus 4.8 (35.9%). Fable 5 falls back to Opus 4.8 on 9% of AA-Omniscience questions.
🔮 Fable 5 Changes the Claude Honesty Playbook
For years, Anthropic's flagship models followed a consistent philosophy: moderate accuracy + low hallucination. Claude 4.1 Opus scored near zero hallucination on AA-Omniscience but answered fewer questions correctly. Opus 4.8 continued this with 35.9% hallucination and 46.6% accuracy — calibrated, cautious, honest about uncertainty.
Fable 5 breaks the pattern. With 61% accuracy, it surpasses GPT-5.5 (57%) to become the most factually knowledgeable model ever tested. But the cost is higher hallucination — Anthropic hasn't published the exact rate, but AA explicitly notes the score is "driven by leading accuracy, rather than low hallucinations." Fable 5 also falls back to the more cautious Opus 4.8 on 9% of questions flagged by safety classifiers.
The practical implication: Fable 5 is the first Claude model where you should verify its output rather than trust its calibration. It knows more than any model — but like GPT-5.5, it will confidently tell you things that aren't true. For unattended agents where silent errors cost money, Opus 4.8's 35.9% hallucination rate at lower accuracy may still be the safer choice. For research, analysis, and complex reasoning where you'll check the output, Fable 5's knowledge breadth is unmatched.
Recently added to AA-Omniscience (June 2026): Claude Fable 5 (40 Index, 61% accuracy) and Claude Opus 4.8 (27.4, 46.6% accuracy, 35.9% hallucination). Still pending: Claude Haiku 4.5, GPT-5.5 (Instant), GPT-5.4 Mini (Instant), Gemini 3 Flash, DeepSeek V4 Pro, DeepSeek V4 Flash, Grok 4.1 Fast, GLM-5V Turbo, Qwen 3.6 Flash.
Provider-Level Analysis: Does Hosting Matter?
Some models show different hallucination rates depending on which provider you use (OpenRouter vs DeepInfra vs Together.ai). This is a new phenomenon in 2026 — quantization, system prompts, and inference configuration at the provider level all influence grounding. Based on OpenRouter Vectara data:
- DeepSeek V4 Pro on OpenRouter: 8.6% — matches official score
- DeepSeek V3.2 on DeepInfra: 5.8% — slightly better (less aggressive quantization?)
- Llama 3.3 70B on Together.ai: 4.9% vs 4.1% on OpenRouter — difference of ~20%
Takeaway: For latency-critical pipelines, the provider matters. A 20% hallucination delta can be the difference between reliable automation and a broken workflow.
Composite Honesty Ranking
Blending both Vectara HHEM and AA-Omniscience into a single honesty score — from most to least trustworthy among capable general-purpose models. Note: Claude Fable 5's position is based on its #1 AA-Omniscience score (40) and 61% accuracy — but with the caveat that its hallucination rate is higher than Opus 4.8's, making it accuracy-driven rather than calibrated-honesty-driven:
- 🥇 Claude Fable 5 🆕 — 61% accuracy + 40 AA-Omniscience (#1); unprecedented knowledge breadth. Accuracy-driven — hallucinates more than Opus 4.8. Best for: complex reasoning where you'll verify output.
- 🥈 GPT-5.4 Mini — 5.5% Vectara; best summarization honesty among capable models. Best for: high-fidelity summarization pipelines.
- 🥉 GPT-5.5 — 9.3% Vectara + 20.1 AA-Omniscience; best all-rounder. Best for: general coding with fact grounding.
- Gemini 3.1 Pro — AA-Omniscience 32.9 (now #2); best at admitting ignorance. Best for: knowledge work where "I don't know" is preferable to fabrication.
- Claude Opus 4.8 — AA-Omniscience 27.4 with 35.9% hallucination; classic calibrated Anthropic honesty. Best for: unattended agents where silent errors cost money.
- DeepSeek V4 Pro — 8.6% Vectara; strong summarization, Omniscience pending
- MiniMax M2.7 — ~9.1% Vectara (M2.5 proxy); Omniscience pending
- Gemini 3.5 Flash — 22.7 AA-Omniscience; strong calibration, Vectara pending
- Grok 4.3 — 18.3 AA-Omniscience; solid calibration, Vectara pending
Small models (GPT-5.4 Nano 3.1%, Qwen3 8B 4.8%, Gemini Flash Lite 3.3%) excluded. Claude Fable 5: AA-Omniscience Index 40 with 61% accuracy — but AA notes this is "driven by leading accuracy, rather than low hallucinations." Its hallucination rate is higher than Opus 4.8 (35.9%). Fallback to Opus 4.8 on 9% of AA-Omniscience questions. Vectara score pending.
What This Means for Developers
✅ DO
- Use GPT-5.4 Mini or GPT-5.5 (Instant) for high-fidelity summarization pipelines
- Use base models (not reasoning) for any fact-grounded generation
- Verify provider-level hallucination rates — they differ meaningfully
- Layer a verification pass (second model checking the first) for high-stakes output
- Check both Vectara and AA-Omniscience — they measure different failure modes
❌ DON'T
- Don't use reasoning mode for summarization — 2-3× more fabrication
- Don't trust a model just because it's "smarter" or more expensive
- Don't use o3-pro or Grok 4 Fast for fact-grounded tasks (20–23% hallucination)
- Don't assume open-weight = less truthful — it varies per model
- Don't ignore the refusal-to-answer gap (MiniMax M2.7: 1.0 Omniscience for M2.5 predecessor)
- Don't be fooled by small-model hallucination scores — GPT-5.4 Nano at 3.1% looks great but can barely code. Low hallucination ≠ capable model.
The Bottom Line
Three clear patterns emerge from the May 2026 data:
- Among capable models, smaller is often more truthful. GPT-5.4 Mini (5.5%) beats GPT-5.5 (9.3%) and Claude Opus 4.7 (12.0%) by wide margins. But don't extrapolate this to the smallest models — GPT-5.4 Nano (3.1%) and Qwen3 8B (4.8%) score even lower on hallucination, but they are not general-purpose coding/reasoning models and their low hallucination rates reflect limited capability, not superior honesty.
- Reasoning mode is a hallucination amplifier. Across all three model families with reasoning variants (GPT, DeepSeek, Grok), the pattern is identical: 2-3× higher hallucination. Chain-of-thought is powerful for math and coding, but actively harmful for factual summarization.
- Provider matters. The same model on OpenRouter vs DeepInfra can show a 20% hallucination delta. Developers building reliable pipelines should benchmark the specific provider endpoint, not just the model card.
The hallucination problem isn't solved — but the data now tells us where to look. Choose your model based on the task, not the brand. Use CodingFleet's Code Assistant to layer verification passes across models.
📚 Related Articles
🚀 Test These Models on CodingFleet →
Sources: Vectara HHEM Hallucination Leaderboard (GitHub, last updated May 11, 2026) | Artificial Analysis Omniscience Index (via BenchLM, May 25, 2026 snapshot) | Suprmind — AI Hallucination Rates & Benchmarks | Digital Applied — 5-Model Study. Scores are point-in-time and may shift with model updates. Models released after mid-May 2026 (Opus 4.8, Gemini 3.5 Flash, Grok 4.3, Qwen 3.7 Max) are not yet independently evaluated on Vectara. All data publicly available at respective provider dashboards.