
Two models at opposite ends of the price spectrum. Claude Sonnet 5 — Anthropic's new mid-tier king, June 30, 63.2% Pro, $3/$15. DeepSeek V4 Pro — the MIT-licensed budget champion, April 24, 55.4% Pro, $0.435/$0.87. On every shared coding benchmark, Sonnet leads by 5-9 points. But DeepSeek fights back with the #1 LiveCodeBench score globally (93.5%), a 3206 Codeforces rating, MIT open-weight license, and pricing that's 6.9× cheaper on input and 17.2× cheaper on output. One model writes better production code. The other writes cheaper code — 7.8× cheaper per task — and you can self-host it. Here's the complete comparison, sourced from Anthropic's Sonnet 5 System Card and DeepSeek's V4 Pro Model Card. Test both on CodingFleet.
TL;DR — Sonnet 5 vs DeepSeek V4 Pro
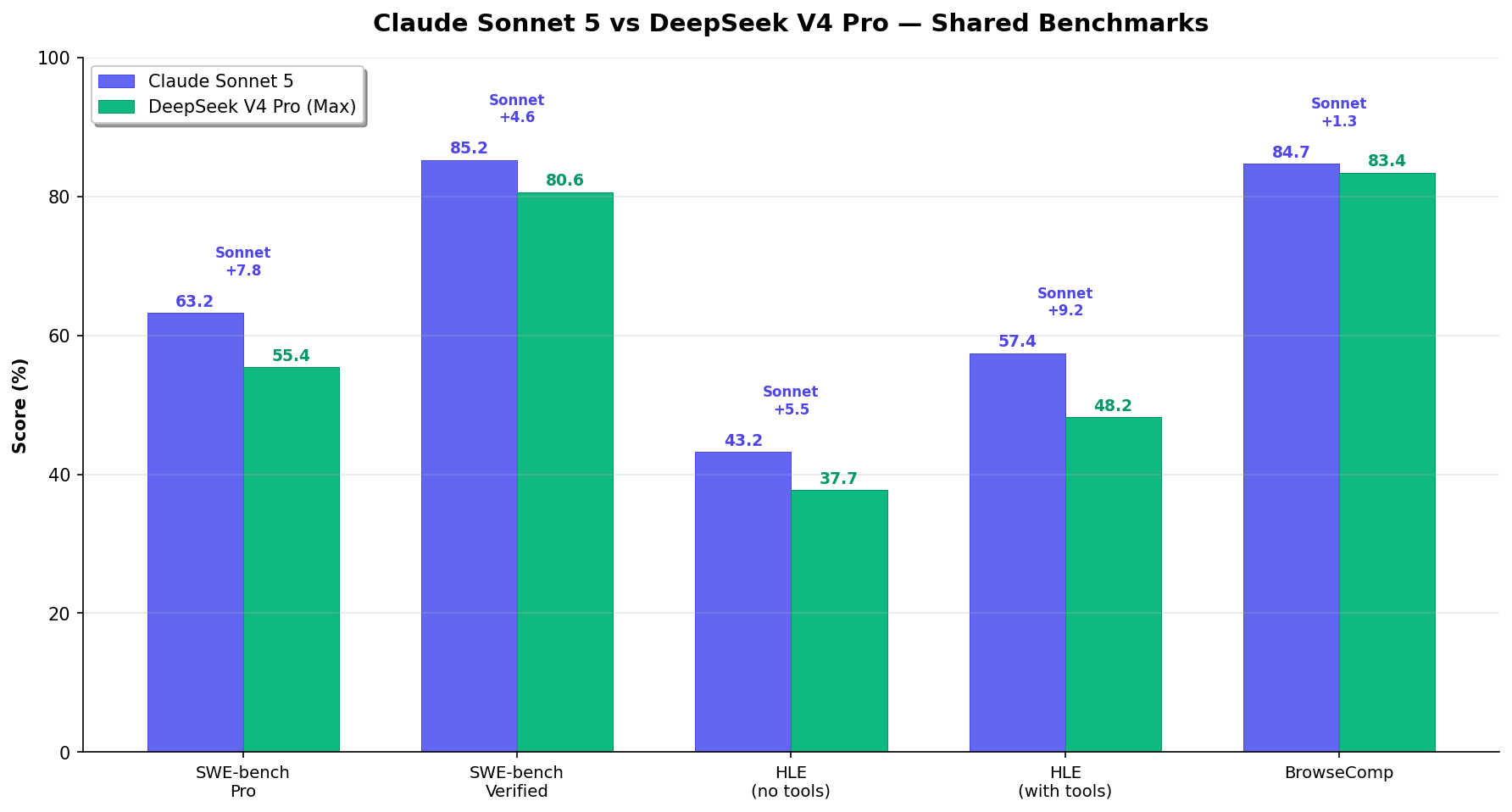
- Sonnet leads every shared coding benchmark: +7.8 Pro, +4.6 Verified, +9.2 HLE with tools, +1.3 BrowseComp. Decisive.
- DeepSeek dominates competitive programming: 93.5% LiveCodeBench (#1 GLOBAL), 3206 Codeforces (#23 human). Unmatched.
- DeepSeek is 6.9–17.2× cheaper: $0.435/$0.87 vs $3/$15. Permanent 75% discount. MIT license. Self-hostable.
- Sonnet leads HLE with tools by 9.2 points: 57.4% vs 48.2%. The widest gap. Tool-augmented reasoning is Sonnet's strongest edge.
- DeepSeek: 1.6T MoE, MIT open-weight: 49B active parameters. Downloadable. Fine-tunable. Air-gappable.
- Terminal-Bench versions differ: Sonnet 80.4% on TB 2.1 vs DeepSeek 67.9% on TB 2.0. Not directly comparable.
Head-to-Head: Shared Benchmarks
| Benchmark | Claude Sonnet 5 | DeepSeek V4 Pro (Max) | Winner |
|---|---|---|---|
| SWE-bench Pro | 63.2% | 55.4% | Sonnet (+7.8) |
| SWE-bench Verified | 85.2% | 80.6% | Sonnet (+4.6) |
| HLE (no tools) | 43.2% | 37.7% | Sonnet (+5.5) |
| HLE (with tools) | 57.4% | 48.2% | Sonnet (+9.2) |
| BrowseComp (agentic search) | 84.7% | 83.4% | Sonnet (+1.3) |
Sonnet 5 from Anthropic System Card. DeepSeek V4 Pro from DeepSeek Model Card (Max reasoning mode). Both vendor-reported. Cross-vendor comparisons are directional. Terminal-Bench excluded: different versions (2.1 vs 2.0).
Coding: Sonnet's Decisive Lead
Every shared benchmark goes to Sonnet, and the margins aren't marginal. On SWE-bench Pro: 63.2% vs 55.4% — a 7.8-point gap. On SWE-bench Verified: 85.2% vs 80.6% (+4.6). On BrowseComp: 84.7% vs 83.4% (+1.3 — the closest fight).
The 7.8-point Pro gap on 1,865 tasks represents roughly 145 additional GitHub issues solved correctly. For production coding where correctness matters — CI/CD pipelines, code review, production bug fixes — Sonnet 5 is the clearly better choice.
Totalum's analysis frames it bluntly: on SWE-bench Pro, "Claude" wins. The Pro benchmark rewards the kind of multi-file, long-horizon debugging that defines professional software engineering — and that's where Anthropic's training pipeline has the clearest edge.
Competitive Programming: DeepSeek's Undisputed Territory
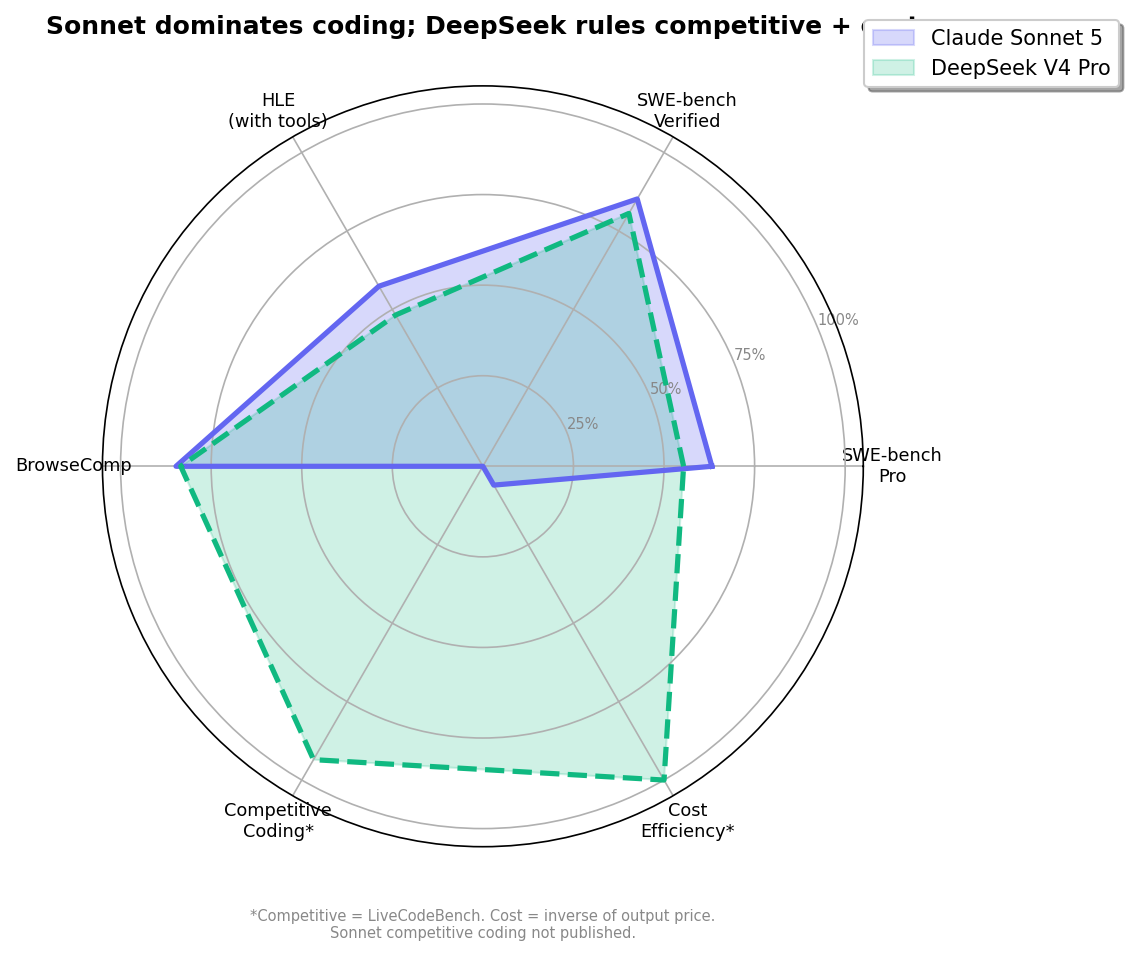
This is where the comparison inverts completely. DeepSeek V4 Pro scores 93.5% on LiveCodeBench — the #1 score of any model globally, open or closed. It beats Claude Opus 4.8 (88.8%), GPT-5.5 (not published at this level), and every other model tracked. Its Codeforces rating of 3206 ranks approximately #23 among human competitive programmers. DeepInfra: "In maximum reasoning effort mode, V4-Pro-Max competes directly with leading closed-source systems."
Sonnet 5 has not published LiveCodeBench or Codeforces scores. This is DeepSeek's uncontested territory — and for developers doing algorithmic work, competitive programming, or optimization-heavy coding, it's a genuine differentiator.
| Competitive Benchmark | Claude Sonnet 5 | DeepSeek V4 Pro (Max) |
|---|---|---|
| LiveCodeBench (Pass@1) | — (not published) | 93.5% — #1 GLOBAL |
| Codeforces Rating | — (not published) | 3206 — #23 human |
| GPQA Diamond | — (not published) | 90.1% |
| HMMT Feb 2026 | — (not published) | 95.2% |
| IMOAnswerBench | — (not published) | 89.8% |
| MMLU-Pro | — (not published) | 87.5% |
| MRCR 1M (long context) | — (not published) | 83.5% |
HLE with Tools: The 9.2-Point Chasm
Humanity's Last Exam with tools is the most realistic measure of how models perform when they can use browsers, terminals, and code execution. Sonnet 5 scores 57.4%. DeepSeek V4 Pro scores 48.2%. That's a 9.2-point gap — the widest on any shared benchmark. This is where Anthropic's investment in agentic tool use pays off most visibly.
Without tools, the gap narrows to 5.5 points (43.2% vs 37.7%). This pattern — Sonnet's lead widens when tools are available — is consistent with Anthropic's design philosophy. Sonnet 5 was built for Claude Code, not for answering trivia questions.
Cost: DeepSeek is 7.8× Cheaper per Task
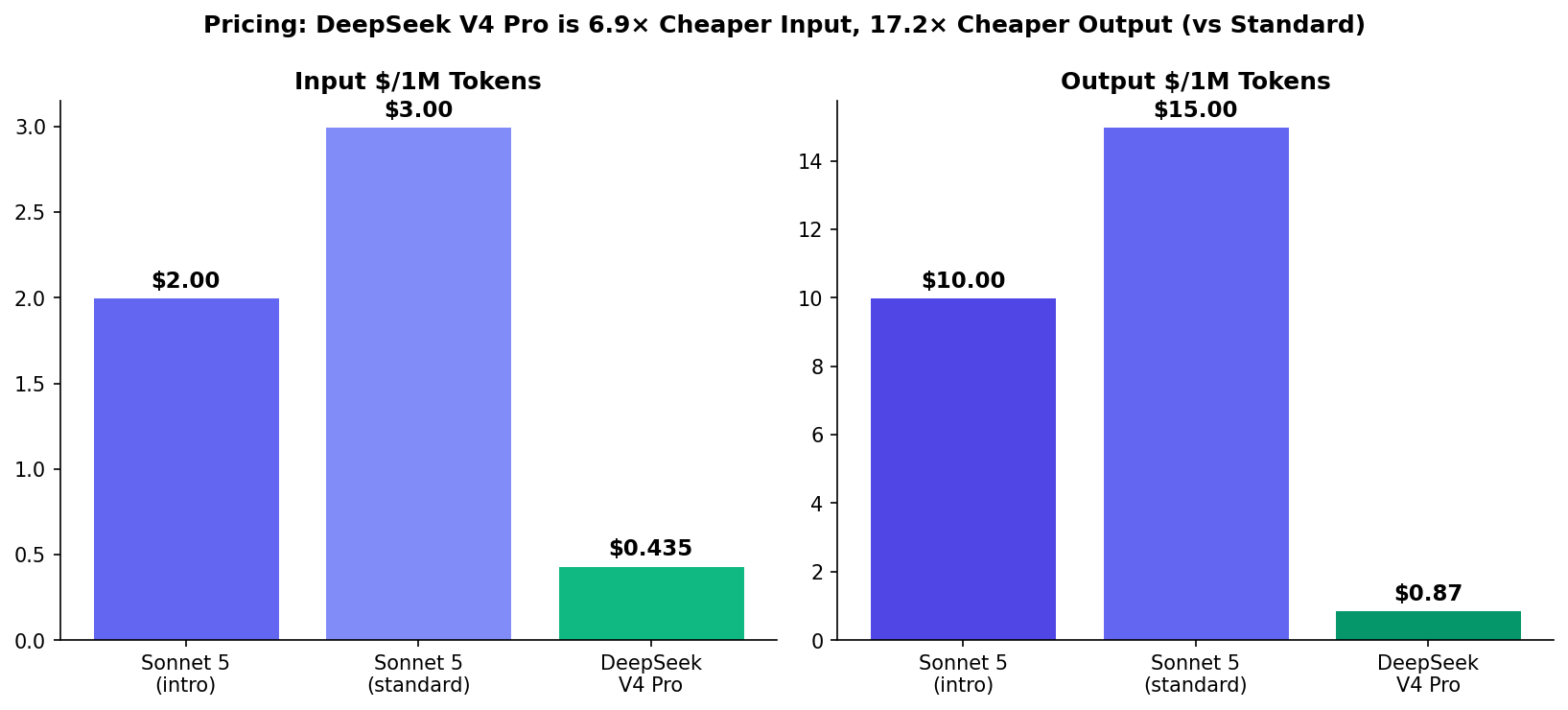
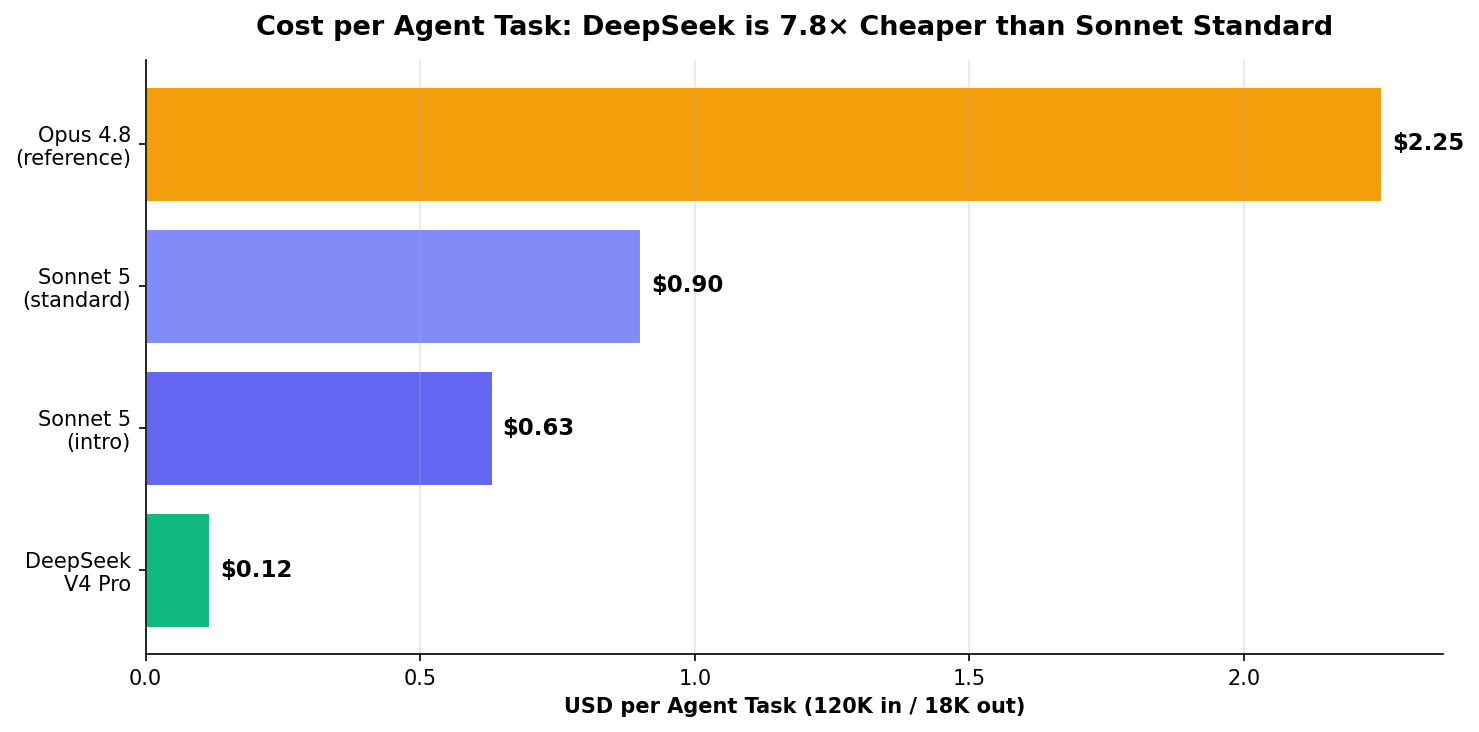
For teams running high-volume agent pipelines, this math is transformative. At $0.12/task, you can run DeepSeek V4 Pro on every commit, every PR, every CI job — not just the important ones. At $0.90/task for Sonnet 5 standard, you're making prioritization decisions about which code gets AI review.
MIT Open-Weight: The Ultimate Differentiator
DeepSeek V4 Pro is fully open-weight under the MIT license. 1.6 trillion total parameters, 49 billion active (Mixture of Experts). You can download the weights, fine-tune on proprietary codebases, run on your own infrastructure, and never pay a per-token fee. Sonnet 5 is proprietary — Anthropic API only.
For startups shipping AI features, enterprises with data sovereignty requirements, and developers who want to own their infrastructure, this difference is larger than any benchmark gap. The model you can self-host beats the model you rent — if you have the infrastructure to run it.
The Radar: Quality vs Quantity
Specification Comparison
| Feature | Claude Sonnet 5 | DeepSeek V4 Pro |
|---|---|---|
| Provider | Anthropic (San Francisco) | DeepSeek (Hangzhou) |
| Released | June 30, 2026 | April 24, 2026 |
| License | Proprietary | MIT (open-weight) |
| Architecture | — (undisclosed) | 1.6T MoE (49B active) |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 128K (300K batch) | 128K |
| Thinking Modes | Adaptive (effort levels) | Non-Think / High / Max |
| Multimodal | Text + Image input | Text only |
| Input Price | $2 intro / $3 std | $0.435 (permanent discount) |
| Output Price | $10 intro / $15 std | $0.87 (permanent discount) |
| Self-hostable | No | Yes (MIT, 1.6T weights) |
| Competitive Edge | SWE-bench, HLE, safety | LiveCodeBench #1, Codeforces 3206 |
Sources: DeepSeek Model Card, DeepInfra overview, Claude Platform Docs.
Should You Use Sonnet 5 or DeepSeek V4 Pro?
| If you... | Decision |
|---|---|
| Need the best production code quality | 🔷 Sonnet 5. +7.8 Pro. Better at real-world SWE. |
| Want the cheapest possible agent at scale | ✅ DeepSeek V4 Pro. $0.12/task vs $0.90. |
| Do competitive programming / algorithms | ✅ DeepSeek V4 Pro. 93.5% LiveCodeBench #1 global. |
| Need to self-host or fine-tune | ✅ DeepSeek V4 Pro. MIT license. 1.6T weights available. |
| Need tool-augmented reasoning | 🔷 Sonnet 5. +9.2 HLE with tools. The widest gap. |
| Run CI/CD on every commit | ✅ DeepSeek V4 Pro. 7.8× cheaper. Run everywhere. |
| Value safety transparency | 🔷 Sonnet 5. 145-page System Card. |
| Need Claude Code ecosystem | 🔷 Sonnet 5. Native integration. |
| Use both strategically (routing) | ✅ Sonnet for quality, DeepSeek for volume. |
Conclusion: Quality Costs 7.8× More. Is It Worth It?
Claude Sonnet 5 and DeepSeek V4 Pro represent the clearest price-vs-quality tradeoff in the current model landscape. Sonnet leads every shared coding benchmark by 5-9 points — it's objectively better at software engineering. DeepSeek is 6.9–17.2× cheaper, MIT open-weight, and the global #1 on competitive programming.
The question isn't which model is better. It's whether the 7.8-point Pro gap is worth 7.8× the cost per task. For production code that ships to users — yes. For CI/CD on every commit, algorithmic exploration, or volume-bound agent pipelines — probably not.
DeepSeek's positioning: open-weight, MIT, permanent 75% discount, algorithmic dominance. Anthropic's positioning: the best coding model at Sonnet prices, with unmatched safety infrastructure. Both true. Both useful. The smart money runs both — Sonnet for quality-critical code review, DeepSeek for everything else.
🔬 Side-by-Side Test
Run Claude Sonnet 5 and DeepSeek V4 Pro on your own code. Is the 7.8× premium worth 7.8 more Pro points? Only your codebase knows.
🔄 Compare Side by Side →Sources & Links
- Anthropic — Claude Sonnet 5 System Card — Table 8.1.A capability evaluation summary
- Anthropic — Introducing Claude Sonnet 5 — official launch announcement
- DeepSeek — V4 Pro Model Card (Hugging Face) — full benchmark table, architecture, license
- DeepInfra — DeepSeek V4 Pro Model Overview
- Totalum — DeepSeek V4 Pro vs Claude: Coding Agent Showdown
- Redreamality — DeepSeek V4 Benchmarks Guide
- NIST — CAISI Evaluation of DeepSeek V4 Pro
- CodingFleet — GLM-5.2 vs DeepSeek V4 Pro
- Claude Platform Docs — Models Overview
Read This Next
- Claude Sonnet 5 vs Opus 4.8 — 93% of the power at 60% of the price
- Claude Sonnet 5 vs GLM 5.2 — MIT vs Proprietary, near-ties everywhere
- Claude Sonnet 5 vs Qwen 3.7 Max — the coder vs the marathon runner