
Two models launched 41 days apart. Claude Sonnet 5 — Anthropic's new mid-tier king, June 30, 63.2% Pro, $3/$15. Qwen 3.7 Max — Alibaba's "Agent Frontier," May 19, 60.6% Pro, $1.25/$3.75. On shared benchmarks, Sonnet leads by slim margins (+2.6 Pro, +4.8 Verified, +1.8 HLE). But Qwen fights back with world-class math (GPQA 92.4%, HMMT 97.1%), proven 35-hour autonomous operation, and a price tag that's 2.7× cheaper on output. One model writes your code. The other runs marathons. Here's the complete comparison, sourced from Anthropic's Sonnet 5 System Card and Qwen's official blog. Test both on CodingFleet.
TL;DR — Sonnet 5 vs Qwen 3.7 Max
- Sonnet leads shared coding benchmarks: +2.6 Pro, +4.8 Verified, +1.8 HLE. Slim but consistent.
- Qwen dominates math: 92.4% GPQA, 97.1% HMMT, 98.3% AIME. Math reasoning is not close.
- Qwen is 2.7× cheaper on output: $3.75 vs $15 standard. 2.4× cheaper on input ($1.25 vs $3).
- Qwen: the Agent Frontier: 35-hour autonomous kernel optimization. 96% Kernel Bench win rate. Unmatched agentic stamina.
- Sonnet: the Anthropic ecosystem: OSWorld 81.2%, BrowseComp 84.7%, 145-page System Card, Claude Code native.
- Terminal-Bench versions differ: Sonnet 80.4% on TB 2.1 vs Qwen 69.7% on TB 2.0. Not directly comparable.
Head-to-Head: Shared Benchmarks
| Benchmark | Claude Sonnet 5 | Qwen 3.7 Max | Winner |
|---|---|---|---|
| SWE-bench Pro | 63.2% | 60.6% | Sonnet (+2.6) |
| SWE-bench Verified | 85.2% | 80.4% | Sonnet (+4.8) |
| HLE (no tools) | 43.2% | 41.4% | Sonnet (+1.8) |
Sonnet 5 from Anthropic System Card. Qwen 3.7 Max from Qwen Official Blog and DataCamp analysis. Both vendor-reported. Cross-vendor comparisons are directional — different scaffolds introduce uncertainty. Terminal-Bench excluded: Sonnet uses TB 2.1, Qwen uses TB 2.0 (different task sets, not comparable).
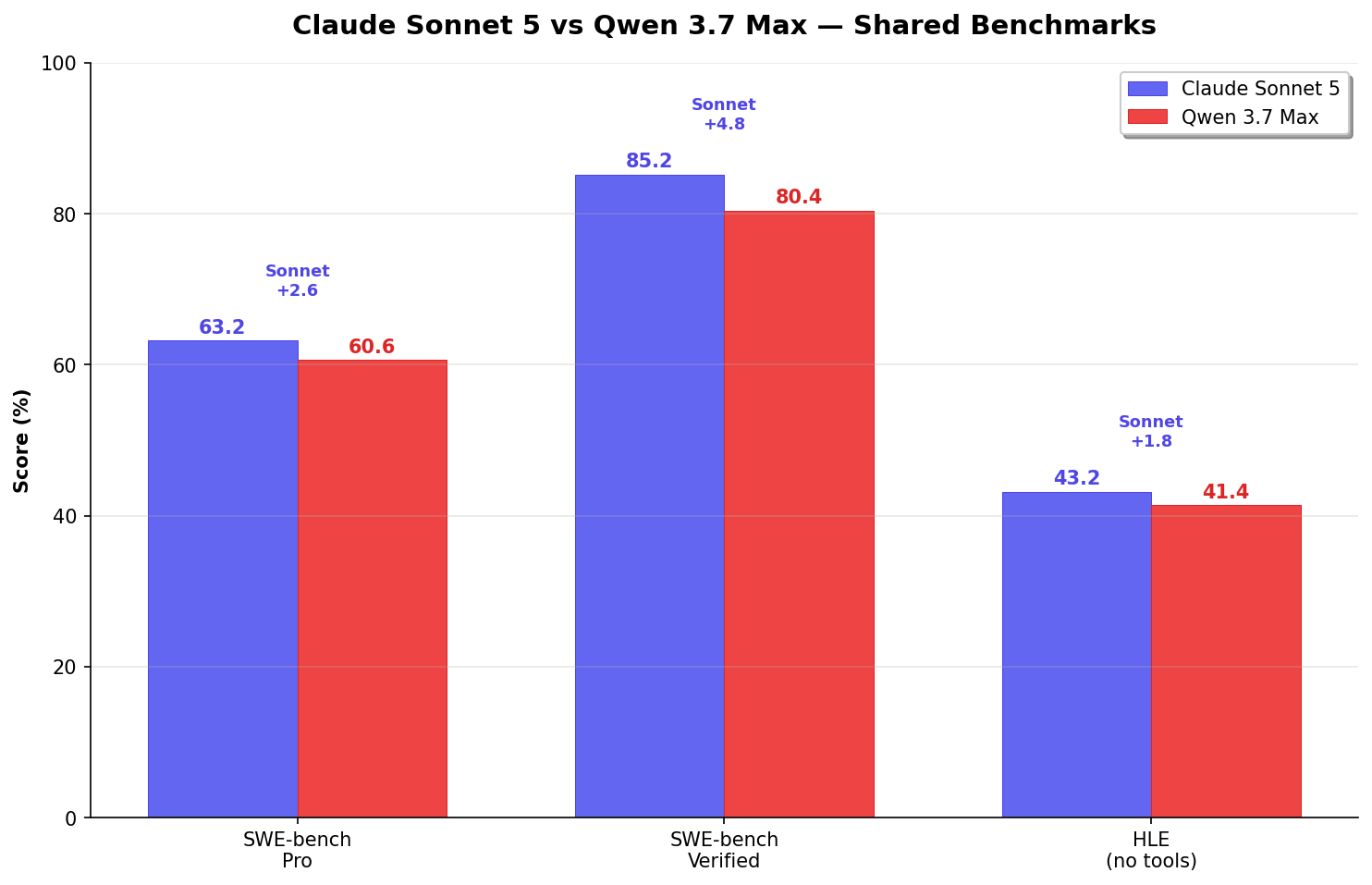
Coding: Sonnet's Modest Edge
On SWE-bench Pro — the benchmark that matters most for production coding — Sonnet 5 leads 63.2% to 60.6%. That's a 2.6-point gap. On SWE-bench Verified (the classic 500-problem set): Sonnet at 85.2% vs Qwen at 80.4% (+4.8). On HLE without tools (raw reasoning): Sonnet at 43.2% vs Qwen at 41.4% (+1.8).
These are real leads, but they're not decisive. A 2.6-point Pro gap on 1,865 tasks is ~48 tasks. For most development workflows, both models will handle the vast majority of coding tasks competently. Sonnet gets the edge on the hardest bugs; Qwen gets the edge on affordability.
The Terminal-Bench comparison is unfortunately apples-to-oranges. Sonnet 5 scores 80.4% on Terminal-Bench 2.1 (the current standard, same harness used for Opus 4.8 and GPT-5.5). Qwen 3.7 Max scores 69.7% on Terminal-Bench 2.0 (an older, different task set). The version gap makes direct comparison unreliable. DataCamp's analysis: "This benchmark tests autonomous terminal-based software engineering with a 5-hour timeout and 12 CPU cores. On SWE-Pro, it scores 60.6, the highest in the comparison table."
Math: Qwen's Dominance
This is where the comparison flips. Qwen 3.7 Max is a math powerhouse:
| Math Benchmark | Claude Sonnet 5 | Qwen 3.7 Max |
|---|---|---|
| GPQA Diamond (PhD science) | — (not published) | 92.4% |
| HMMT Feb 2026 (competition math) | — (not published) | 97.1% |
| AIME 2026 | — (not published) | 98.3% |
| IMOAnswerBench | — (not published) | 90.0% |
| LiveCodeBench (competitive coding) | — (not published) | 91.6% |
| USAMO 2026 (proof-based) | 79.5% | — (not published) |
GPQA Diamond at 92.4% is elite — competitive with Opus 4.8 and GPT-5.5. HMMT at 97.1% and AIME at 98.3% are ceiling scores. For math-heavy coding (scientific computing, algorithmic work, formal verification), Qwen 3.7 Max has a clear advantage. Sonnet 5's USAMO score (79.5%) is impressive in its own right, but Anthropic didn't publish GPQA Diamond or competition math benchmarks for this model — they focused the System Card on agentic coding and safety instead.
Agentic Autonomy: Qwen's 35-Hour Marathon
This is Qwen's signature capability — and it's something no other model in this class can claim. Yotta Labs' coverage of Qwen's launch:
"A 35-hour autonomous kernel optimization run on T-Head ZW-M890 PPUs. Across 432 kernel evaluations and 1,158 tool calls, the model finished with a 10x geometric mean speedup. Most agent models stop making progress after a few hours. Qwen 3.7-Max sustained meaningful progress past 30 hours."
And during an 86-hour RL training session, the model autonomously flagged 1,618 reward hacking cases and added 13 new heuristic rules to its own training loop. Kernel Bench L3: 96% win rate. This is the "Agent Frontier" label in action — Qwen 3.7 Max is built for unattended, long-horizon autonomous operation.
Sonnet 5's agentic capabilities are strong (80.4% TB 2.1, 81.2% OSWorld), but Anthropic hasn't demonstrated the kind of multi-hour autonomous endurance that Qwen has proven. If your workflow involves overnight agent runs or continuous autonomous optimization, Qwen's track record matters.
Pricing: Qwen is 2.7× Cheaper on Output
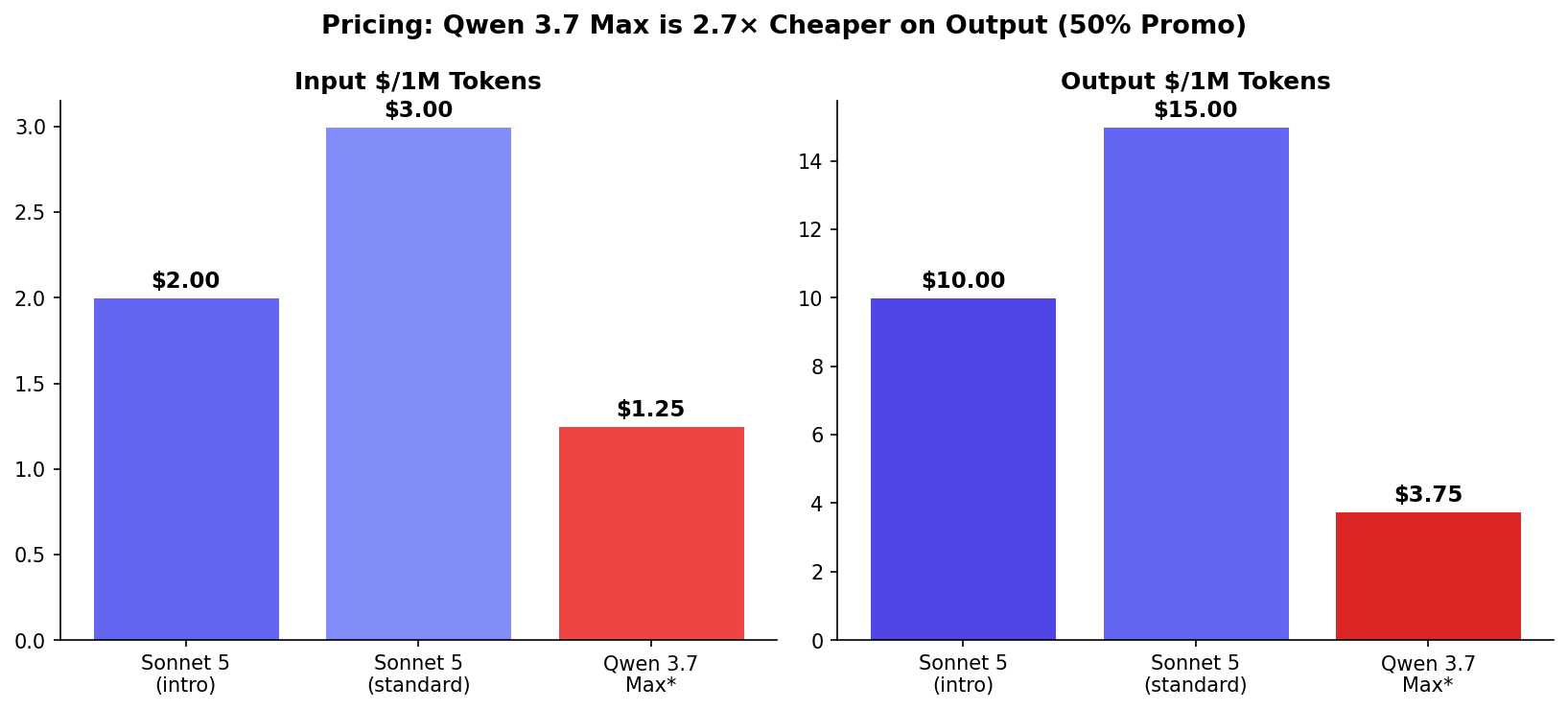
For a workload of 10M input + 1M output tokens per day:
| Model | Daily Cost | Monthly Cost |
|---|---|---|
| Qwen 3.7 Max | $16.25 | ~$488 |
| Sonnet 5 (introductory) | $30.00 | ~$900 |
| Sonnet 5 (standard) | $45.00 | ~$1,350 |
Assumes 90% input / 10% output split, 0.5× thinking multiplier, no caching. Qwen promotional pricing.
At $488/month for Qwen vs $1,350/month for Sonnet 5 standard, the annual difference is ~$10,300. That's real money for teams running production agents.
The Radar: Coding vs Math + Autonomy
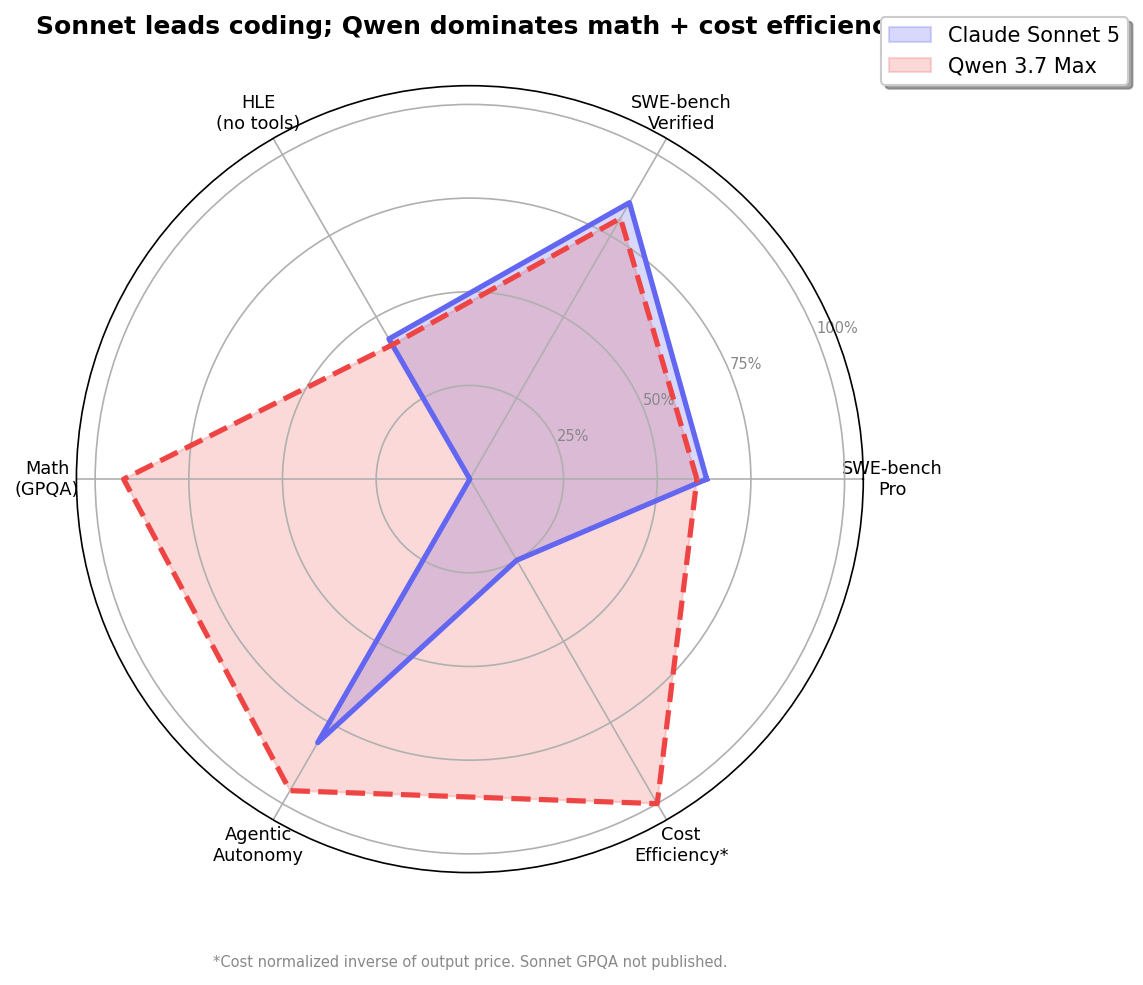
Where They Don't Overlap
| Benchmark | Claude Sonnet 5 | Qwen 3.7 Max |
|---|---|---|
| OSWorld-Verified (computer use) | 81.2% | — (not published) |
| BrowseComp (agentic search) | 84.7% | — (not published) |
| GDPval-AA v2 (knowledge work) | 1618 Elo | — (not published) |
| MCP Atlas (tool orchestration) | — (not published) | 76.4% (Qwen harness) |
| GPQA Diamond | — (not published) | 92.4% |
| Kernel Bench L3 | — (not published) | 96% WR |
| LiveCodeBench | — (not published) | 91.6% |
Specification Comparison
| Feature | Claude Sonnet 5 | Qwen 3.7 Max |
|---|---|---|
| Provider | Anthropic (San Francisco) | Alibaba / Qwen (Hangzhou) |
| Released | June 30, 2026 | May 19, 2026 |
| License | Proprietary | Proprietary |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 128K (300K batch) | 128K |
| Thinking | Adaptive (effort levels) | Thinking model (reasoning) |
| Multimodal | Text + Image input | Text only |
| API Compatibility | Native Anthropic API | OpenAI + Anthropic compatible |
| Input Price | $2 intro / $3 std | $1.25 (50% promo)* |
| Output Price | $10 intro / $15 std | $3.75 (50% promo)* |
| Agentic Highlight | Claude Code ecosystem | 35hr autonomous runs |
*Qwen 3.7 Max promotional pricing: 50% off through June 22, 2026. Standard pricing: $2.50/$7.50. Both OpenAI and Anthropic API compatible. Sources: Qwen Official Blog, Yotta Labs.
Should You Use Sonnet 5 or Qwen 3.7 Max?
| If you... | Decision |
|---|---|
| Do heavy coding / Claude Code daily | 🔷 Sonnet 5. +2.6 Pro, +4.8 Verified. Better coder. |
| Need the cheapest near-frontier coding | ✅ Qwen 3.7 Max. 2.7× cheaper output. $488/mo vs $1,350. |
| Do math-heavy work / scientific computing | ✅ Qwen 3.7 Max. 92.4% GPQA. Math dominance. |
| Run long-horizon autonomous agents | ✅ Qwen 3.7 Max. 35-hr proven. 96% Kernel Bench. |
| Need computer use / GUI automation | 🔷 Sonnet 5. 81.2% OSWorld. Qwen unpublished. |
| Value safety transparency | 🔷 Sonnet 5. 145-page System Card. |
| Want Anthropic ecosystem integration | 🔷 Sonnet 5. Claude Code, Cowork, claude.ai default. |
| Need competitive coding / algorithms | ✅ Qwen 3.7 Max. 91.6% LiveCodeBench. |
| Run both strategically (routing) | ✅ Best of both. Sonnet for code, Qwen for math + autonomy. |
Conclusion: The Coder vs The Marathon Runner
Claude Sonnet 5 and Qwen 3.7 Max represent two different answers to the question "what should a near-frontier model excel at?" Sonnet 5 is the better coder — +2.6 Pro, +4.8 Verified, deep Anthropic ecosystem integration, and the safety infrastructure that enterprises trust. It's the model you want reviewing your pull requests.
Qwen 3.7 Max is the better autonomous agent — 35-hour proven endurance, world-class math, 2.7× cheaper, and OpenAI/Anthropic API compatible. It's the model you want running overnight optimization jobs and tackling algorithmic heavy lifting.
Qwen's positioning: "The Agent Frontier." Anthropic's positioning: "The best combination of speed and intelligence." Both true. The 2.6-point Pro gap makes Sonnet the better coder. The 2.7× price gap makes Qwen the better value. Your choice depends on whether you value marginal coding quality or substantial cost savings — and whether you need a model that writes code or one that runs marathons.
🔬 Side-by-Side Test
Run Claude Sonnet 5 and Qwen 3.7 Max on your own code. Coder vs marathon runner — your benchmarks are the only ones that matter.
🔄 Compare Side by Side →Sources & Links
- Anthropic — Claude Sonnet 5 System Card — Table 8.1.A capability evaluation summary
- Anthropic — Introducing Claude Sonnet 5 — official launch announcement
- Qwen Official Blog — Qwen 3.7 Max — benchmark comparison table, Agent Frontier claims
- DataCamp — Qwen 3.7 Max: Features, Benchmarks, Agent Capabilities
- Yotta Labs — Qwen 3.7 Max: Pricing, Features, Access
- CodingFleet — GLM-5.2 vs Qwen 3.7 Max
- Pioneer AI — How to Choose the Best Coding Models (2026)
- Claude Platform Docs — Models Overview
Read This Next
- Claude Sonnet 5 vs Opus 4.8 — 93% of the power at 60% of the price
- Claude Sonnet 5 vs Gemini 3.5 Flash — coding depth vs tool orchestration speed
- Claude Sonnet 5 vs GLM 5.2 — MIT vs Proprietary, near-ties everywhere