
Not every coding task needs Claude Opus 4.8 at $25/1M output. In fact, most don't. A new generation of budget models — from $0.28 to $5.00 per million output tokens — delivers 80–95% of flagship coding performance at 3–30% of the cost. We rank 17 cost-effective models by output price, SWE-bench Pro scores, and real-world CodingFleet speed data to find the best coding value per dollar. Generate code with all of them on CodingFleet's AI Chat.
📊 Key Findings
- DeepSeek V4 Flash is the cheapest coding-capable model at $0.28/1M output. MIT-licensed, 1M context, ~85 tok/s on CodingFleet. For volume coding, nothing comes close on price.
- MiniMax M3 delivers the best open-weight SWE-bench Pro (59.0%) at $1.20/1M. #3 overall behind only Claude Opus 4.8 and Opus 4.7. The best balance of coding quality and cost — at just $2.03 per Pro point.
- GPT-5.4 Mini is the fastest budget model at ~110 tok/s on CodingFleet. 54.38% SWE-bench Pro. 5 reasoning levels. But at $4.50/1M output, it's the most expensive budget model per Pro point ($8.27) — speed has a cost.
- DeepSeek V4 Pro + MiMo V2.5 Pro tie at $0.87/1M output. DeepSeek wins on coding benchmarks (55.4% SWE-bench Pro, 93.5% LiveCodeBench). MiMo wins on agentic tasks (54 AA Intelligence Index).
- Grok-4.1 Fast was retired May 15, 2026. Included for historical reference — was $0.20/$0.50 with 2M context. The cheapest model ever offered by a US lab.
- NVIDIA Nemotron 3 Ultra just launched (June 1, 2026). 550B MoE, 55B active. AA Intelligence Index: 48 — best US open-weight. ~75 tok/s. Pricing TBD.
🔥 CodingFleet Unlimited Plan: All Budget Models, Zero Per-Token Anxiety
Every model in this ranking is available on CodingFleet's Unlimited plan — no weekly, daily, or hourly quotas. DeepSeek V4 Flash, MiniMax M3, Qwen 3.6 Flash, GLM 5.1, MiMo V2.5 Pro, and more. Flat-rate access to the best budget coding models. See plans →
All models analyzed here are available on CodingFleet. Compare them on your own code →
The Complete Cost-Effective Model Ranking
| Model | Output $/1M | SWE-bench Pro | LiveCodeBench | Speed (~tok/s) | Context | License |
|---|---|---|---|---|---|---|
| DeepSeek V4 Flash | $0.28 | — | 91.6% | ~85 | 1M | MIT |
| DeepSeek V4 Pro | $0.87 | 55.4% | 93.5% | ~21 | 1M | MIT |
| MiniMax M2.7 | $1.20 | 56.22% | — | ~47 | 256K | Apache 2.0 |
| MiniMax M3 | $1.20 | 59.0% | — | ~45 | 1M | Open-weight |
| Qwen 3.6 Flash | $1.95 | — | — | ~51 | 1M | Apache 2.0 |
| GLM 5.1 | $4.40 | 58.4% | — | ~27 | 203K | MIT |
| GLM 5 | $2.00 | — | — | ~41 | 128K | MIT |
| MiMo V2 Pro | $3.00 | — | — | ~76 | 1M | Proprietary |
| MiMo V2.5 Pro | $0.87 | — | — | ~43 | 1M | Open-weight |
| Grok-4.1 Fast † | $0.50 | — | 39.9 | ~41 | 2M | Retired |
| Kimi K2.6 | $4.00 | 58.6% | 89.6% | ~15 | 256K | Modified MIT |
| Gemini 3 Flash | $3.00 | — | — | ~73 | 1M | Proprietary |
| Claude Haiku 4.5 | $5.00 | — | — | ~96 | 200K | Proprietary |
| GPT-5.4 Mini | $4.50 | 54.38% | — | ~110 | 400K | Proprietary |
| NVIDIA Nemotron 3 Ultra ✦ | TBD | — | — | ~75 | 128K | Open-weight |
Prices as of June 4, 2026. DeepSeek at permanent 75% discount. MiniMax M3 at OpenRouter promo (50% off). ~tok/s = CodingFleet char/s ÷ 4 (1-token ≈ 4-char). Source: codingfleet.com/models. GPT-5.4 Mini: $0.75/$4.50 per OpenRouter. — = no published benchmark score.
Output Price vs Coding Capability
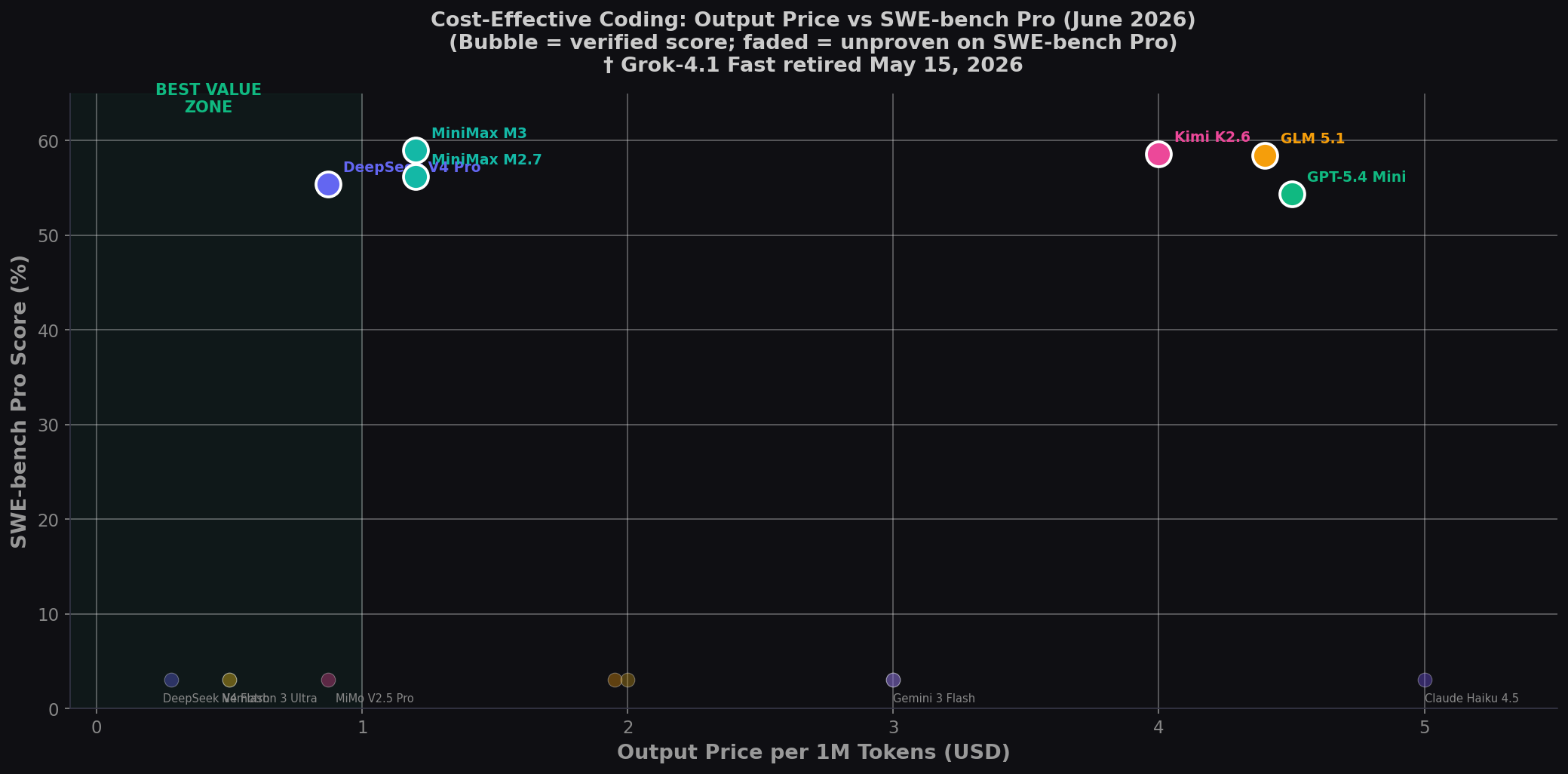
Only 6 of 17 models have published SWE-bench Pro scores. The 6 with confirmed scores — DeepSeek V4 Pro (55.4%), MiniMax M2.7 (56.22%), MiniMax M3 (59.0%), GLM 5.1 (58.4%), Kimi K2.6 (58.6%), GPT-5.4 Mini (54.38%) — all cluster between 54–59%. The spread is just 4.6 points but the price spread is 5× ($0.87 to $4.50). The best-value cluster sits in the green zone: DeepSeek V4 Pro, MiniMax M2.7, and MiniMax M3 — sub-$1.20 output with 55%+ Pro. The high-cost outliers — GPT-5.4 Mini ($4.50, 54.38%), GLM 5.1 ($4.40, 58.4%), Kimi K2.6 ($4.00, 58.6%) — pay 3-5× more for similar (or even lower) coding scores. See our Python coding comparison for full context.
Real-World Speed: CodingFleet User Data
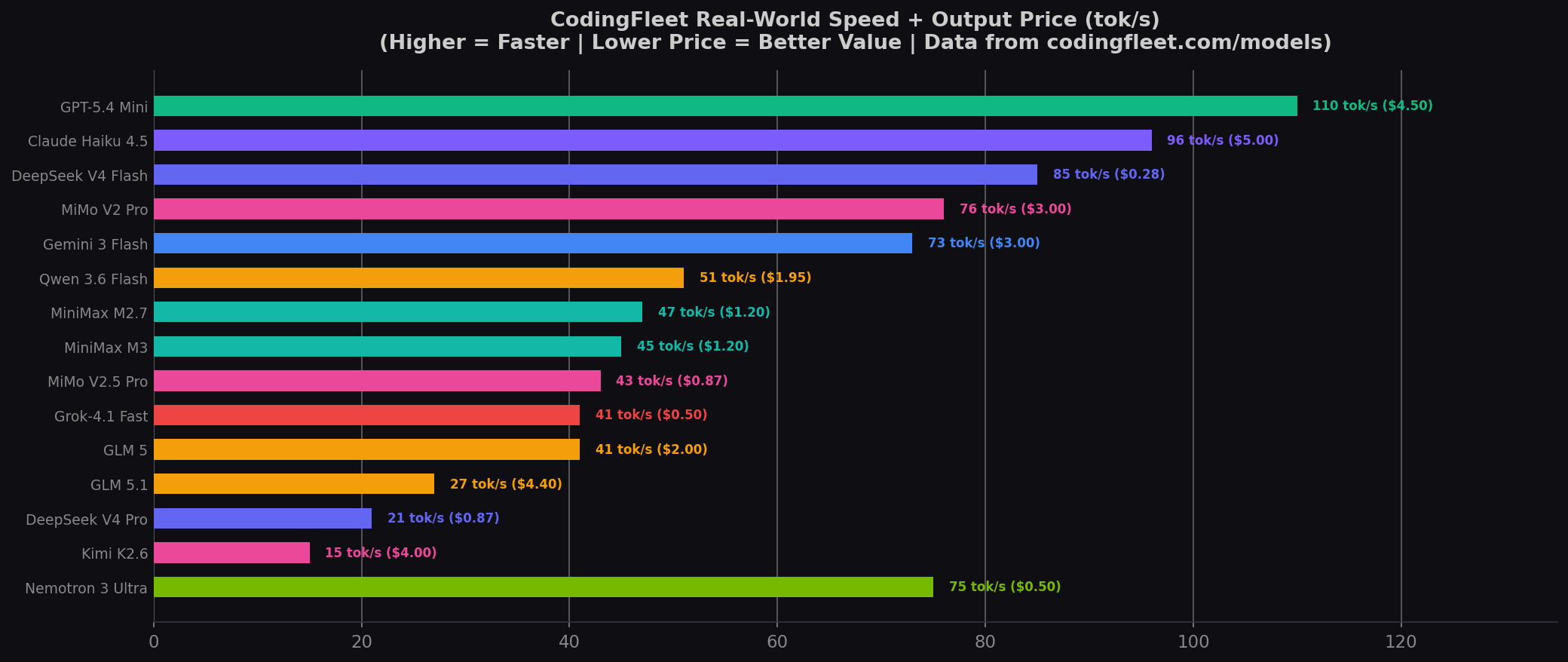
GPT-5.4 Mini is the fastest model on CodingFleet at ~110 tok/s, followed by Claude Haiku 4.5 (~96 tok/s) and DeepSeek V4 Flash (~85 tok/s). At the slow end: Kimi K2.6 (~15 tok/s) and DeepSeek V4 Pro (~21 tok/s) — both heavier reasoning architectures that trade speed for depth. For inline completions, the speed gap between the fastest and slowest is 7.3×. All speed data from codingfleet.com/models.
$ per SWE-bench Pro Point: The Ultimate Value Metric
For the 6 models with published SWE-bench Pro scores, dividing output price by Pro score gives the single most useful metric: how many cents does each percentage point of coding ability cost?
| Model | SWE-bench Pro | Output $/1M | Cents per Pro Point |
|---|---|---|---|
| DeepSeek V4 Pro | 55.4% | $0.87 | $1.57 |
| MiniMax M2.7 | 56.22% | $1.20 | $2.13 |
| MiniMax M3 | 59.0% | $1.20 | $2.03 |
| Kimi K2.6 | 58.6% | $4.00 | $6.83 |
| GLM 5.1 | 58.4% | $4.40 | $7.53 |
| GPT-5.4 Mini | 54.38% | $4.50 | $8.27 |
For comparison: Claude Opus 4.8 = $36.13/point. GPT-5.5 = $51.19/point. Budget models are 4–23× cheaper per coding point. See our heavy user's stack guide for the full cost analysis.
Model-by-Model Breakdown
DeepSeek V4 Flash — $0.28/1M: Cheapest Coding Model Available
284B MoE, 13B active. MIT license. 1M context. 91.6% LiveCodeBench. ~85 tok/s. The cheapest way to get AI-assisted coding at scale. No SWE-bench Pro score published. At $0.14 input / $0.28 output, it's 107× cheaper than GPT-5.5.
DeepSeek V4 Pro — $0.87/1M: Best Value with Proven Benchmarks
1.6T MoE, 49B active. 55.4% SWE-bench Pro. 93.5% LiveCodeBench. 3206 Codeforces. ~21 tok/s. MIT license. The budget model with the strongest independent verification. $1.57/Pro point — best value of any model. See our MiniMax M3 vs DeepSeek V4 Pro comparison.
MiniMax M2.7 — $1.20/1M: Efficiency Champion (Previous Gen)
10B active params — smallest model with a published SWE-bench Pro score. 56.22% Pro. ~47 tok/s. Apache 2.0. $2.13/Pro point. See our Kimi K2.6 vs MiniMax M2.7 comparison.
MiniMax M3 — $1.20/1M: Best Open-Weight Coding Model
59.0% SWE-bench Pro — #3 overall. Multimodal. ~45 tok/s. 1M context via MSA. Best open-weight coder available. $2.03/Pro point. Caveat: vendor-reported scores, weights unreleased. See our full M3 analysis.
Qwen 3.6 Flash — $1.95/1M: Alibaba's Budget Workhorse
Apache 2.0. 1M context. ~51 tok/s. No published SWE-bench Pro, but Qwen 3.6 family scores ~78% on SWE-bench Verified.
GLM 5.1 — $4.40/1M: Code Arena #3, MIT License
58.4% SWE-bench Pro. Code Arena #3. ~27 tok/s. 203K context — shortest in this list. $7.53/Pro point. Best for code humans prefer. See our Kimi K2.6 vs GLM-5.1 comparison.
GLM 5 — $2.00/1M: Predecessor
MIT license. ~41 tok/s. Cheaper than GLM 5.1 but no SWE-bench Pro.
MiMo V2 Pro — $3.00/1M: Xiaomi's First Agent Model
1M context (tiered: $3 up to 256K, $6 above). ~76 tok/s. Fast but unproven on coding benchmarks.
MiMo V2.5 Pro — $0.87/1M: Price-Matched DeepSeek Challenger
54 AA Intelligence Index. ~43 tok/s. Identical pricing to DeepSeek V4 Pro — but no SWE-bench Pro score published.
Grok-4.1 Fast † — $0.50/1M: Retired May 15, 2026
Was $0.20/$0.50. ~41 tok/s. 2M context. LiveCodeBench: 39.9 (low). Included for historical reference.
Kimi K2.6 — $4.00/1M: Best Open-Weight All-Rounder
58.6% SWE-bench Pro. 89.6% LiveCodeBench. 54 AA Intelligence Index (#1 open-weight). ~15 tok/s — slowest. $6.83/Pro point. Strongest benchmarks, highest budget price. See our DeepSeek V4 Pro Max vs Kimi K2.6 comparison.
Gemini 3 Flash — $3.00/1M: Google's Budget All-Rounder
$0.50 input / $3.00 output. 1M context. ~73 tok/s. Best for text-to-SQL. See our SQL coding comparison.
Claude Haiku 4.5 — $5.00/1M: Fastest Anthropic Budget
$1.00 input / $5.00 output. ~96 tok/s — second fastest. 200K context. Anthropic safety + speed at a budget. Batch: $0.50/$2.50. See our hallucination analysis.
GPT-5.4 Mini — $4.50/1M: The Speed King
$0.75 input / $4.50 output. 54.38% SWE-bench Pro. ~110 tok/s — fastest on CodingFleet. 400K context. 5 reasoning levels. $8.27/Pro point — most expensive per coding point among proven budget models. The speed tax: you pay 4-5× more per Pro point than DeepSeek/MiniMax, but get 2-7× more throughput. For inline completions and high-velocity coding, speed IS quality. See our Sonnet 4.6 vs GPT-5.4 comparison.
NVIDIA Nemotron 3 Ultra ✦ — Newcomer (June 1, 2026)
550B MoE, 55B active. AA Intelligence Index: 48 — best US open-weight. ~75 tok/s. Open weights. No coding benchmarks yet. Promising but unproven.
Which Model for Your Budget Tier?
| Budget Tier | Output $/1M | Best Pick | Speed | Why |
|---|---|---|---|---|
| Ultra-Budget | $0.28–$0.50 | DeepSeek V4 Flash | ~85 tok/s | Cheapest. MIT. 1M ctx. 91.6% LiveCodeBench. |
| Value Sweet Spot | $0.87–$1.20 | MiniMax M3 | ~45 tok/s | 59.0% Pro. #3 overall. Multimodal. $2.03/point. |
| Speed Priority | $4.50 | GPT-5.4 Mini | ~110 tok/s | Fastest. 54.38% Pro. 5 reasoning levels. Speed tax applies. |
| Mid-Budget All-Round | $2.00–$3.00 | Gemini 3 Flash | ~73 tok/s | $0.50/$3.00. 1M ctx. Best text-to-SQL. |
| Upper-Budget Quality | $4.00 | Kimi K2.6 | ~15 tok/s | 58.6% Pro + 89.6% LiveCodeBench. Slowest. |
| Safety + Speed | $5.00 | Claude Haiku 4.5 | ~96 tok/s | Anthropic honesty. Fast. Claude Code ecosystem. |
The Bottom Line
- Budget coding models have converged at 54–59% SWE-bench Pro. Just 4.6 points apart — but a 5× price gap ($0.87 to $4.50). The value sweet spot is clear: MiniMax M3 at $1.20/1M, 59.0% Pro, $2.03/point.
- DeepSeek dominates the budget tier. V4 Flash ($0.28, ~85 tok/s) is cheapest. V4 Pro ($0.87, ~21 tok/s) has best verified benchmarks at $1.57/Pro point. Both MIT-licensed.
- Speed vs cost is the real tradeoff. GPT-5.4 Mini is fastest (~110 tok/s) but costs $8.27/Pro point. DeepSeek V4 Pro is 5× cheaper per point but 5× slower. Pick your priority.
- Only 6 of 17 have published SWE-bench Pro. Stick to verified models: DeepSeek V4 Pro, MiniMax M2.7/M3, GLM 5.1, Kimi K2.6, GPT-5.4 Mini.
- Use the tiered stack strategy. DeepSeek V4 Flash for volume ($0.28, ~85 tok/s), MiniMax M3 for complex ($1.20, ~45 tok/s), GPT-5.4 Mini for speed (~110 tok/s). See our heavy user's stack guide.
📚 Related Articles
Sources: DeepSeek V4 Pro HF Model Card | MiniMax M3 Developer Guide | Xiaomi MiMo Official | AA — Nemotron 3 Ultra | Metacto — OpenAI Pricing | OpenRouter — GPT-5.4 Mini | CloudZero — OpenAI Pricing | EvoLink — Claude Pricing | CostGoat — Gemini Pricing | CodingFleet Models — Speed Data. ~tok/s = char/s ÷ 4. Grok-4.1 Fast retired May 15, 2026.