
Both priced at $15 per million output tokens. Both released within two weeks of each other (February/March 2026). Both are the mid-tier workhorses that most developers actually use — not the $25–30 flagship models that dominate headlines. But Claude Sonnet 4.6 and GPT-5.4 are optimized for completely different things. GPT-5.4 leads Terminal-Bench by 16 points and SWE-bench Pro by ~14 points. Sonnet counters with a 90% cache discount, no long-context surcharge, and the mature Claude Code ecosystem. If you're paying $15/1M for your daily coding model, here's which one to pick — and when to use both. Test them side by side on CodingFleet's AI Chat.
📊 Key Findings
- GPT-5.4 is the stronger model on raw benchmarks. SWE-bench Pro: 57.7% vs ~43.6%. Terminal-Bench: 75.1% vs 59.1%. For complex multi-step coding tasks, GPT-5.4 has the edge.
- In real-world CodingFleet usage, GPT-5.4 is also faster. 242.5 char/s (~61 tok/s) in standard mode vs Sonnet 4.6 at 173.3 char/s (~43 tok/s). In thinking mode: GPT-5.4 Thinking High at 157.1 char/s (~39 tok/s) vs Sonnet 4.6 Thinking at 140.1 char/s (~35 tok/s). Based on actual CodingFleet user data.
- Sonnet wins on cost at scale. No long-context surcharge (GPT-5.4 doubles above 272K). 90% cache discount vs GPT-5.4's 50%. Mature Claude Code ecosystem with sub-agent architecture.
- Sonnet leads on MCP Atlas (69.5%) and GDPval-AA (1676 Elo). GPT-5.4 leads OSWorld (75.0%), BrowseComp (82.7%), and native web search. Different agentic strengths.
- GPT-5.4 has 5 reasoning levels; Sonnet has adaptive thinking. GPT-5.4's xhigh reasoning is meaningfully stronger than its standard mode. Sonnet's adaptive thinking is automatic — simpler interface, less to configure.
All models analyzed here are available on CodingFleet. Start a new chat → and compare them on your own code.
Specifications: The Tale of the Tape
| Spec | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|
| Release Date | February 17, 2026 | March 5, 2026 |
| Input Price | $3.00/1M | $2.50/1M |
| Output Price | $15.00/1M | $15.00/1M |
| Cached Input | $0.30/1M (90% off) | $1.25/1M (50% off) |
| Batch API | $1.50 / $7.50 | $1.25 / $7.50 |
| Context Window | 200K (standard) / 1M (beta) | 270K (standard) / 1.05M |
| Long-Context Surcharge | None | 2× above 272K tokens |
| Max Output | 64K tokens | 128K tokens |
| Speed (non-thinking) ★ | 173.3 char/s (~43 tok/s) | 242.5 char/s (~61 tok/s) |
| Speed (thinking mode) ★ | 140.1 char/s (~35 tok/s) | 157.1 char/s (~39 tok/s) |
| Reasoning | Adaptive thinking (auto) | 5 levels: mini → xhigh |
| Computer Use | Yes (72.5% OSWorld) | Yes (75.0% OSWorld) |
| Web Search | Needs integration | Native |
| Multimodal | Text + Image | Text + Image + File |
★ Speed data from CodingFleet's real-world user metrics — not third-party estimates. Conversion: 1 token ≈ 4 characters. GPT-5.4 non-thinking is the fastest mid-tier model measured on CodingFleet.
Benchmark Comparison
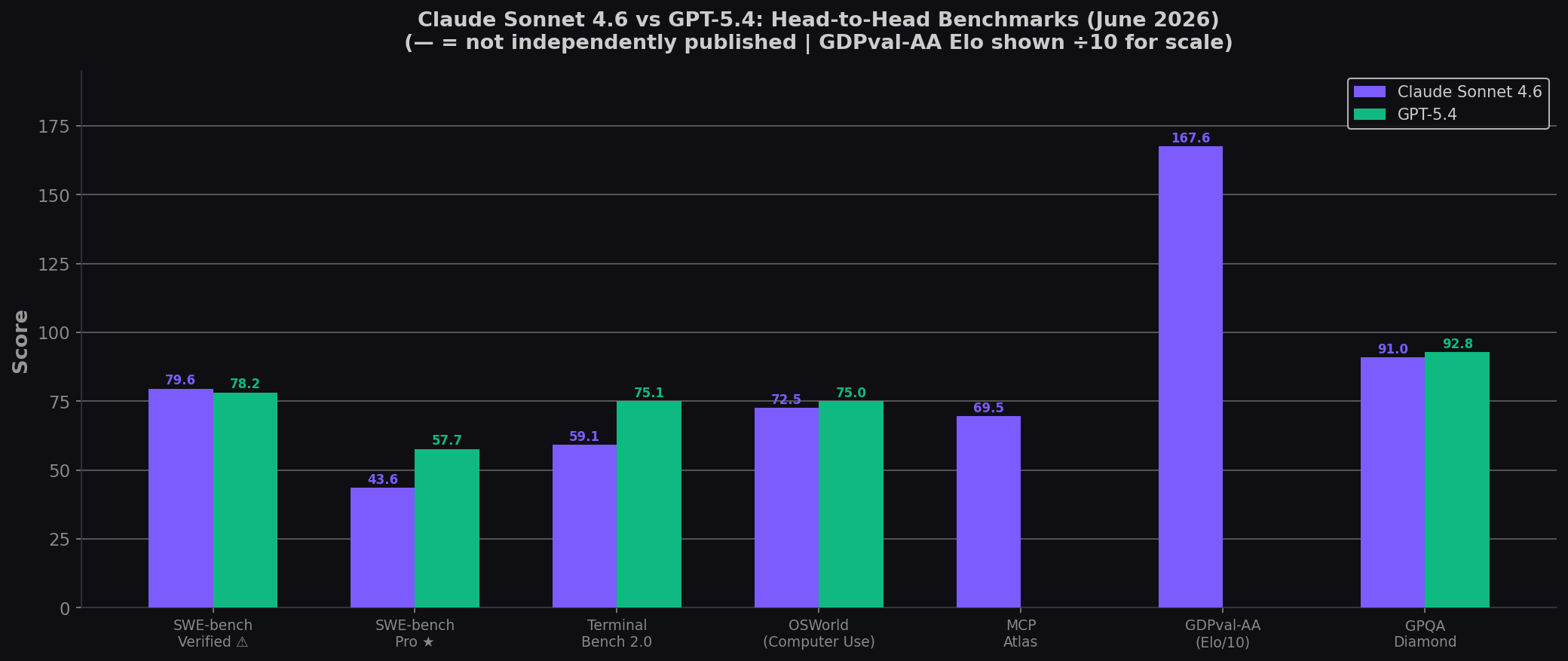
| Benchmark | Claude Sonnet 4.6 | GPT-5.4 | Winner |
|---|---|---|---|
| SWE-bench Verified ⚠️ | 79.6% | 78.2% | Sonnet (close) |
| SWE-bench Pro ★ | ~43.6% (SEAL est.) | 57.7% | GPT-5.4 (+14) |
| Terminal-Bench 2.0 | 59.1% | 75.1% | GPT-5.4 (+16) |
| OSWorld-Verified | 72.5% | 75.0% | GPT-5.4 (close) |
| MCP Atlas | 69.5% | — | Sonnet |
| GDPval-AA (Elo) | 1676 | — | Sonnet |
| BrowseComp | — | 82.7% | GPT-5.4 |
| GPQA Diamond | ~91% | 92.8% | GPT-5.4 (close) |
| HLE (no tools) | — | 39.8% | GPT-5.4 |
| ARC-AGI-2 | 60.4% | 73.3% | GPT-5.4 |
⚠️ SWE-bench Verified contaminated per OpenAI (Feb 2026). ★ Pro is the recommended benchmark. Sonnet 4.6 SWE-bench Pro estimated from SEAL leaderboard (Sonnet 4.5: 43.6%); not yet independently published by Anthropic. Sources: Vals.ai; Anthropic Sonnet 4.6 system card; OpenAI GPT-5.4 announcement.
The headline: On the most important coding benchmarks, GPT-5.4 leads. SWE-bench Pro (+14 points) and Terminal-Bench (+16 points) are meaningful gaps. But Sonnet fights back on MCP Atlas, GDPval-AA, and Claude Code's ecosystem — domains where Anthropic's maturity advantage shows.
Real-World Speed: CodingFleet User Data
⚡ The Speed Narrative Gets a Reality Check
Third-party benchmarks suggest Sonnet is 2–3× faster than GPT-5.4. Actual CodingFleet user data tells a different story. Based on real-world usage across thousands of developers (codingfleet.com/models):
| Model | char/s | ~tok/s | Total Tokens Served |
|---|---|---|---|
| GPT-5.4 (non-thinking) | 242.5 | ~61 | 133.6M |
| Claude Sonnet 4.6 (non-thinking) | 173.3 | ~43 | 700.1M |
| GPT-5.4 Thinking High | 157.1 | ~39 | 374.1M |
| Claude Sonnet 4.6 Thinking | 140.1 | ~35 | 2.3B |
GPT-5.4 is the fastest mid-tier model on CodingFleet. In non-thinking mode, it delivers ~61 tok/s vs Sonnet's ~43 tok/s — a 42% speed advantage. In thinking mode, the gap narrows to ~39 vs ~35 tok/s. The narrative that "Sonnet is faster" appears to come from third-party benchmarks that may not reflect production API performance.
Volume insight: Sonnet 4.6 Thinking has served 2.3B tokens on CodingFleet — the most of any model in this comparison. GPT-5.4 non-thinking at 133.6M tokens suggests it's used differently: quick, fast completions rather than long agentic sessions. The usage patterns reinforce the complementary nature of these models.
Where GPT-5.4 Wins: Terminal, Reasoning & Speed
Terminal-Bench 2.0: 75.1% vs 59.1% (+16 points)
This is the widest gap between these two models on any benchmark. Terminal-Bench tests real CLI workflows — installing packages, debugging configurations, chaining build commands. GPT-5.4's 75.1% is only 3.1 points behind GPT-5.5 (78.2%). GPT-5.4 is the most cost-effective terminal automation model available. For DevOps, CI/CD, and infrastructure-as-code, GPT-5.4 at $15/1M delivers near-flagship terminal performance at half the price. See how terminal skills transfer to database administration in our SQL coding comparison.
SWE-bench Pro: 57.7% vs ~43.6% (estimated)
GPT-5.4's 57.7% on SWE-bench Pro is essentially tied with GPT-5.5 (58.6%) and Kimi K2.6 (58.6%). For a mid-tier model, this is remarkable — it delivers flagship-level multi-file bug fixing at half the price. Sonnet's Pro score is estimated at ~43.6% based on SEAL leaderboard data for Sonnet 4.5 — a 14-point gap. For production bug fixing, GPT-5.4 is the stronger choice at this price point.
Raw Speed: GPT-5.4 Is Simply Faster
At 242.5 char/s (~61 tok/s) in standard mode, GPT-5.4 is the fastest mid-tier model on CodingFleet. For inline completions, quick refactors, and high-velocity coding sessions, GPT-5.4's speed advantage over Sonnet (~43 tok/s) is tangible. The third-party narrative that Sonnet is faster appears to come from controlled benchmarks that don't match real-world API conditions. Based on actual CodingFleet user data, GPT-5.4 holds a clear 42% speed lead.
Five Reasoning Levels: From Mini to xHigh
GPT-5.4's five-tier reasoning system is its most underrated feature. Mini handles completions. Medium handles refactors. High handles debugging. xHigh handles architecture. This granularity lets you pay for exactly the reasoning depth you need. Sonnet's adaptive thinking is automatic — simpler, but less controllable.
Where Sonnet 4.6 Wins: Cost at Scale and Ecosystem
The Long-Context Surcharge Trap
This is where GPT-5.4's pricing gets misleading. Both models appear to cost $15/1M output. But GPT-5.4 doubles its price above 272K tokens — the exact point where long-context becomes useful. Load a medium-sized codebase (300K tokens) and your effective output cost jumps to $30/1M. Sonnet never charges a surcharge. For context-heavy workflows — whole-repo refactoring, migration planning, multi-file debugging — Sonnet's flat pricing is dramatically cheaper. Read our deep dive on how models actually use 1M tokens.
Cache Discount: 90% vs 50%
Sonnet's 90% cache discount ($0.30/1M cached input) vs GPT-5.4's 50% ($1.25/1M) means Sonnet is far cheaper for repetitive prompts — the pattern of agentic coding where you send the same system prompt and codebase context repeatedly. Over a month of heavy usage, the cache discount alone can cut Sonnet's effective cost by 40–60%.
Developer Preference: 70% Choose Sonnet Over Sonnet 4.5
According to claudefa.st model comparison data, 70% of developers prefer Sonnet 4.6 over Sonnet 4.5 and 59% over Opus 4.5. This isn't benchmark noise — it's sustained developer preference across thousands of real coding sessions. Sonnet 4.6 is widely considered the best-balanced model in Anthropic's lineup: near-Opus coding quality at one-fifth the price.
Ecosystem: Claude Code vs Codex CLI
| Ecosystem | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|
| Primary IDE Integration | Claude Code, Cursor, VS Code | Codex CLI, GitHub Copilot |
| Agent Scaffolding | Claude Code (mature, multi-agent) | Codex (newer, improving fast) |
| Sub-agent Architecture | Yes (Dynamic Workflows) | Limited (single-agent focus) |
| MCP Integration | Native, deep | Emerging |
| Web Search | Needs integration | Native |
| Computer Use | 72.5% OSWorld | 75.0% OSWorld |
Claude Code's maturity is Sonnet's biggest advantage. The sub-agent architecture, MCP integration, and multi-file orchestration are years ahead of Codex CLI. GPT-5.4 is the stronger raw model with faster real-world speed, but Claude Code's scaffolding can amplify Sonnet's effective capability beyond what benchmark scores suggest. See our Opus 4.8 vs GPT-5.5 comparison for more on how scaffolding affects real-world performance.
Pricing Deep Dive: What You Actually Pay
| Scenario | Claude Sonnet 4.6 | GPT-5.4 | Winner |
|---|---|---|---|
| Standard prompt (50K input, 10K output) | $0.15 + $0.15 = $0.30 | $0.125 + $0.15 = $0.275 | GPT-5.4 |
| Cached prompt (same, 80% cache hit) | $0.03 + $0.15 = $0.18 | $0.075 + $0.15 = $0.225 | Sonnet |
| Long context (300K input, 10K output) | $0.90 + $0.15 = $1.05 | $0.75 + $0.30 = $1.05 | Tie |
| Long context (500K input, 10K output) | $1.50 + $0.15 = $1.65 | $1.25 + $0.30 = $1.55 | Close |
| Batch/Flex processing | $1.50 / $7.50 | $1.25 / $7.50 | GPT-5.4 |
The takeaway: For short, uncached prompts, GPT-5.4 is slightly cheaper. For cached, repetitive prompts (the agentic coding pattern), Sonnet is significantly cheaper. For long-context work, they're surprisingly close — GPT-5.4's surcharge is offset by Sonnet's higher input price. The real differentiators are benchmark strength (GPT-5.4), cache efficiency (Sonnet), and ecosystem maturity (Sonnet).
Which Model for Which Task?
| Task | Better Model | Why |
|---|---|---|
| Complex bug fixing (multi-file) | GPT-5.4 | 57.7% SWE-bench Pro; ~14-point lead |
| Terminal / CLI automation | GPT-5.4 | 75.1% Terminal-Bench; 16-point lead |
| Inline completions (IDE) | GPT-5.4 | 242.5 char/s (~61 tok/s); fastest mid-tier model |
| Agentic loops (tool-heavy) | GPT-5.4 | Stronger tool-use; 75.0% OSWorld; faster speed |
| Batch / async processing | GPT-5.4 | $1.25/$7.50 batch pricing |
| Long-context refactoring (>272K) | Sonnet 4.6 | No surcharge; flat pricing at any context length |
| Cost-sensitive high volume (cached) | Sonnet 4.6 | 90% cache discount; ~40% lower effective cost |
| MCP / tool orchestration | Sonnet 4.6 | Native MCP; 69.5% MCP Atlas; mature ecosystem |
| Code review / PR feedback | Sonnet 4.6 | 70% developer preference; stronger nuance |
| Sub-agent workflows | Sonnet 4.6 | Claude Code Dynamic Workflows; unique to Anthropic |
The Bottom Line
- GPT-5.4 is the stronger model — on benchmarks AND real-world speed. SWE-bench Pro (+14 points), Terminal-Bench (+16 points), and 242.5 char/s (~61 tok/s) on CodingFleet — 42% faster than Sonnet. For raw capability and responsiveness, GPT-5.4 is the better $15 model. The third-party narrative that "Sonnet is 2-3× faster" is contradicted by actual CodingFleet user data.
- Sonnet 4.6 wins on cost at scale. 90% cache discounts. No long-context surcharge. Mature Claude Code ecosystem with sub-agent architecture. For cached, repetitive agentic workflows and context-heavy refactoring, Sonnet's flat pricing and ecosystem maturity are decisive.
- The long-context surcharge is GPT-5.4's hidden cost. Both models cost $15/1M on paper. But GPT-5.4 doubles above 272K tokens. For whole-repo work, Sonnet is often cheaper per task.
- Use both. GPT-5.4 for speed, terminal automation, complex debugging, and reasoning-heavy tasks. Sonnet for long-context work, MCP orchestration, and Claude Code's mature agent scaffolding. The models are complementary — and both cost $15/1M output. CodingFleet gives you both in one platform.
- For heavy users, route by task type. GPT-5.4 for terminal, batch, and speed-sensitive work. Sonnet for cached, long-context, and MCP-heavy workflows. See our heavy user's AI coding stack guide for the full strategy.
📚 Related Articles
Sources: Anthropic — Sonnet 4.6 System Card | Vals.ai — SWE-bench Verified | NxCode — GPT-5.4 Guide | NxCode — Sonnet vs GPT-5.4 | MorphLLM — SWE-bench Pro | CodingFleet Models — Real-World Speed Data. Speed data from actual CodingFleet user metrics (June 2026 snapshot). Sonnet SWE-bench Pro estimate from SEAL leaderboard; not yet independently published by Anthropic.