
Two Chinese open-weight models. Two completely different philosophies. MiniMax M3 launched June 1, 2026 as the first model to combine frontier coding, 1M-token context, and native video/image input in a single open-weight system — scoring 59.0% on SWE-bench Pro (edging GPT-5.5's 58.6%). DeepSeek V4 Pro launched April 23 as the MIT-licensed algorithmic specialist — 93.5% LiveCodeBench, 3206 Codeforces, with a permanent 75% discount pushing output to $0.87/1M. M3 wins the benchmark scoreboard. DeepSeek wins on price, algorithmic depth, and proven independent verification. Here's the definitive comparison. Test both on CodingFleet's AI Chat.
📊 Key Findings
- MiniMax M3 wins the benchmark scoreboard. SWE-bench Pro: 59.0% vs 55.4% (+3.6). SWE-bench Verified: 85% vs 80.6%. Terminal-Bench 2.1: 66.0% vs 67.9% (DeepSeek wins narrowly). BrowseComp: tie at ~83.5%. On raw coding scores, M3 is the stronger open-weight coder — #3 overall behind only Claude Opus 4.8 and Opus 4.7.
- DeepSeek V4 Pro wins on price and algorithmic depth. $0.87/1M output vs M3's $1.20 (promo) / $2.40 (standard). Cached input: $0.0036 vs $0.06 — 16× cheaper. 93.5% LiveCodeBench, 3206 Codeforces, 95.2% HMMT — M3 has no published scores on any algorithmic/math benchmark.
- M3 is multimodal; DeepSeek is text-only. M3 accepts images, video, and text. DeepSeek is text-only. For UI debugging from screenshots, video walkthroughs, or design-mock-to-code, M3 has a capability DeepSeek simply doesn't offer.
- DeepSeek has 14 providers and MIT-licensed weights available NOW. M3 runs on 1 provider and weights are promised but unreleased. For self-hosting or air-gapped deployment, DeepSeek is the only option that exists today.
- All M3 benchmarks are vendor-reported. TechTimes flags: "all scores are company-run on MiniMax's own infrastructure." Model weights have not shipped. DeepSeek's scores are independently verified by Vals.ai, BenchLM, and Artificial Analysis.
🔥 CodingFleet Unlimited Plan: Both Models, Unlimited Usage
MiniMax M3 and DeepSeek V4 Pro are both available on CodingFleet's Unlimited plan — no weekly, daily, or hourly quotas. Two open-weight coding models, zero per-token anxiety. Test which one fits your workflow.
All models analyzed here are available on CodingFleet. Compare them on your own code →
Specifications: The Tale of Two Philosophies
| Spec | MiniMax M3 | DeepSeek V4 Pro |
|---|---|---|
| Release Date | June 1, 2026 | April 23, 2026 |
| Architecture | Sparse MoE + MSA (MiniMax Sparse Attention) | MoE + CSA+HCA Hybrid Attention |
| Context Window | 1M tokens | 1M tokens |
| Max Output | 512K tokens | 384K tokens |
| Modalities | Text + Image + Video → Text | Text → Text |
| Input Price (standard) | $0.60/1M | $0.435/1M |
| Output Price (standard) | $2.40/1M | $0.87/1M |
| Promo / Discount | $0.30 / $1.20 (50% off) | $0.435 / $0.87 (permanent 75%) |
| Cached Input | $0.06/1M | $0.0036/1M (16× cheaper) |
| License | Open-weight (promised) | MIT (available now) |
| OpenRouter Providers | 1 | 14 |
| CodingFleet Speed ★ | 179.4 char/s (~45 tok/s) | 85.6 char/s (~21 tok/s) |
Prices as of June 4, 2026. DeepSeek output at permanent 75% discount rate. M3 promo pricing via OpenRouter (50% off). ★ Speed data from CodingFleet's real-world user metrics.
Benchmark Comparison
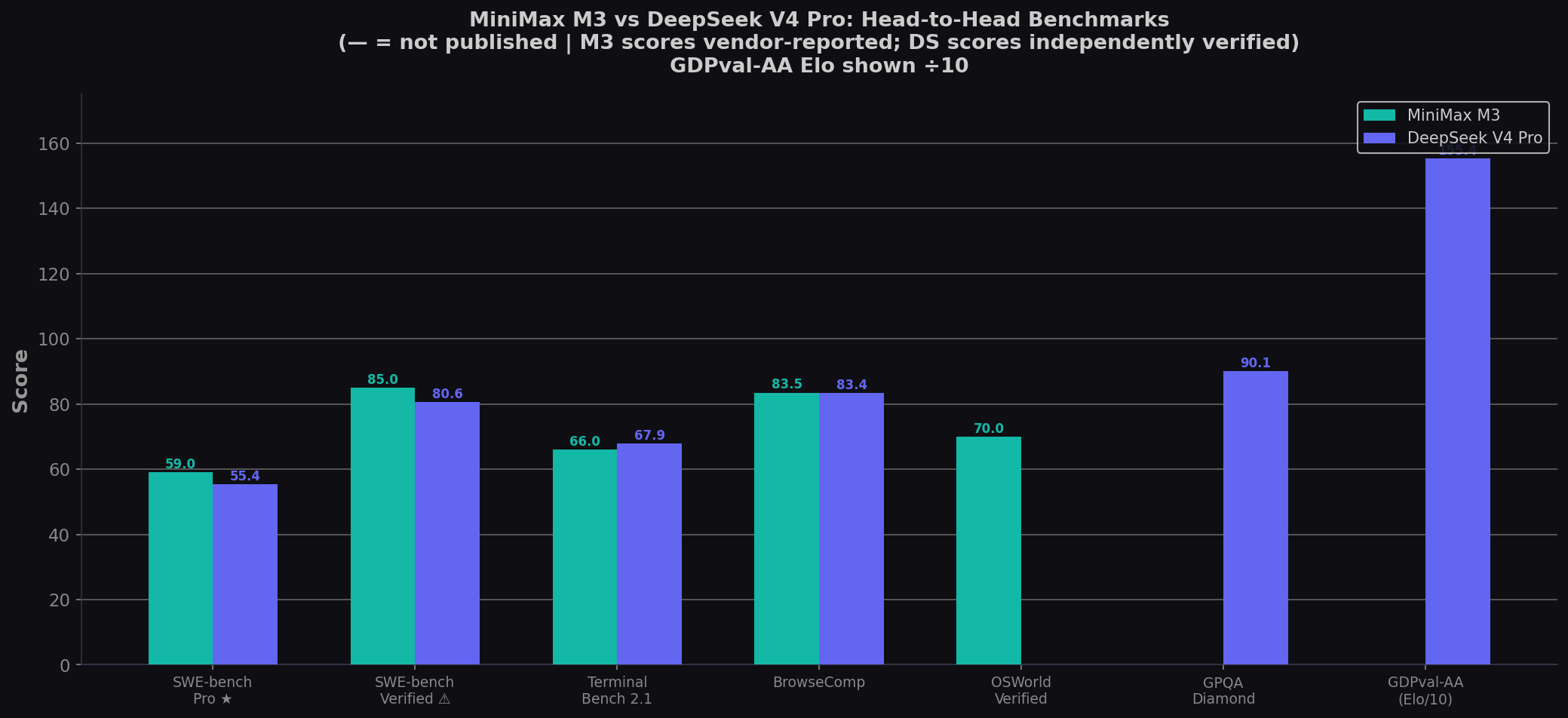
| Benchmark | MiniMax M3 | DeepSeek V4 Pro | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 59.0% | 55.4% | M3 (+3.6) |
| SWE-bench Verified ⚠️ | 85.0% | 80.6% | M3 (+4.4) |
| Terminal-Bench 2.1 | 66.0% | 67.9% | DS (close) |
| BrowseComp | 83.5% | 83.4% | Tie |
| OSWorld-Verified | 70.0% | — | M3 |
| GPQA Diamond | — | 90.1% | DS |
| GDPval-AA (Elo) | — | 1554 | DS |
| LiveCodeBench | — | 93.5% | DS |
| Codeforces Rating | — | 3206 | DS |
| HMMT 2026 Feb | — | 95.2% | DS |
⚠️ SWE-bench Verified contaminated per OpenAI (Feb 2026). ★ Pro is the recommended benchmark. M3 scores vendor-reported (MiniMax infrastructure). DS scores independently verified by Vals.ai, BenchLM, Artificial Analysis. Sources: MiniMax M3 Developer Guide; DeepSeek V4 Pro HF Model Card; BenchLM comparison.
The headline: M3 leads on 4 of 5 directly comparable benchmarks. But DeepSeek has scores on 5 benchmarks where M3 has no published data — GPQA, LiveCodeBench, Codeforces, GDPval-AA, and HMMT. The scoreboard is incomplete: M3 wins where they overlap, but DeepSeek has breadth M3 can't yet match.
Where MiniMax M3 Wins: Raw Benchmarks & Multimodality
SWE-bench Pro: 59.0% — Edges GPT-5.5
This is the headline number. M3's 59.0% on SWE-bench Pro surpasses GPT-5.5 (58.6%), Kimi K2.6 (58.6%), GLM-5.1 (58.4%), and GPT-5.4 (57.7%). It trails only Claude Opus 4.8 (69.2%) and Opus 4.7 (64.3%). For a freshly-launched open-weight model, this is remarkable — it's the #3 model on SWE-bench Pro among all publicly tested models, behind only Anthropic's flagships. See our Python coding comparison for full context.
Native Multimodality: Video Input Changes the Game
M3 is the first open-weight model that natively processes text, images, AND video as input. This isn't a bolt-on — MiniMax rebuilt the data pipeline to scale pre-training to 100 trillion+ tokens with multimodal training from step zero. You can feed M3 a screen recording of a bug, a design mockup, or a video walkthrough of a codebase — and it generates code. DeepSeek V4 Pro is text-only. For UI development, debugging from screenshots, or design-to-code workflows, M3 has a capability DeepSeek doesn't offer at any price.
OSWorld-Verified: 70.0% — Computer Use Leader
M3 scores 70.0% on OSWorld — the benchmark for autonomous computer operation. This trails Claude Opus 4.8 (83.4%) and GPT-5.5 (78.7%) but is competitive with Claude Sonnet 4.6 (72.5%). DeepSeek V4 Pro has no published OSWorld score. For agentic desktop automation, M3 is the strongest open-weight option.
MSA Architecture: 1M Context Without Melting Your GPU
MiniMax Sparse Attention (MSA) is the architectural breakthrough that makes M3 possible. Instead of full attention (where every token attends to every other token — O(n²) complexity), MSA selects relevant KV-blocks, cutting per-token compute at long context to roughly 1/20 the cost of the previous generation at 1M tokens. This is conceptually similar to DeepSeek's CSA+HCA hybrid attention but goes further — it enables native multimodal processing within the same architecture. The M2 series had removed sparse attention entirely; M3 brings it back in a radically more efficient form.
⚠️ The Verification Gap
Every M3 benchmark score is vendor-reported on MiniMax's own infrastructure. TechTimes notes the model weights "have not shipped" as of June 1. This doesn't mean the scores are wrong — but it means independent verification is pending. DeepSeek V4 Pro has been independently benchmarked by Vals.ai, BenchLM, Artificial Analysis, and the OpenRouter community for 6 weeks. Treat M3's scores as promising but unconfirmed until third-party validation arrives.
Where DeepSeek V4 Pro Wins: Price, Algorithmic Depth & Ecosystem
Algorithmic Dominance: 93.5% LiveCodeBench, 3206 Codeforces
DeepSeek V4 Pro holds the #1 LiveCodeBench score (93.5%) and a 3206 Codeforces rating — both elite algorithmic benchmarks where M3 has no published data. Combined with 95.2% on HMMT 2026 (Harvard-MIT Math Tournament) and 90.1% on GPQA Diamond, DeepSeek's strength in structured problem-solving is unmatched among open-weight models. If your coding involves algorithms, data structures, or competitive programming, DeepSeek is in a different league. For generative coding (bug fixing, PRs, multi-file work), M3's SWE-bench Pro lead may be more relevant.
Pricing: The Permanent Advantage
DeepSeek's permanent 75% discount makes it cheaper than M3 at every tier:
- Output: $0.87 vs $1.20 (promo) / $2.40 (standard) — 28–64% cheaper
- Input: $0.435 vs $0.30 (promo) / $0.60 (standard) — M3 promo input is cheaper, but DS standard input beats M3 standard
- Cached input: $0.0036 vs $0.06 — 16× cheaper. For agentic coding with repetitive system prompts, this gap alone can save hundreds of dollars per month.
See our heavy user's AI coding stack guide for the full cost comparison across all models.
Ecosystem Maturity: 14 Providers vs 1
DeepSeek V4 Pro runs on 14 different providers on OpenRouter — you can choose based on latency, reliability, and geographic preference. MiniMax M3 runs on a single provider. For production deployments where uptime and provider redundancy matter, DeepSeek's multi-provider ecosystem is a structural advantage. It also means DeepSeek has been stress-tested at scale across diverse infrastructure — M3 hasn't.
MIT License: Weights Available NOW
DeepSeek V4 Pro's weights are available under the MIT license — the most permissive open-source license. You can download, modify, fine-tune, and commercialize without restrictions. M3's weights are "promised" but unreleased as of June 4, 2026. For self-hosting, air-gapped deployment, or fine-tuning, DeepSeek is the only option that exists today. This also means DeepSeek's scores have been independently reproduced; M3's haven't.
Real-World Speed: CodingFleet User Data
⚡ MiniMax M3 Is 2× Faster on CodingFleet
Based on actual CodingFleet user data (codingfleet.com/models):
| Model | char/s | ~tok/s |
|---|---|---|
| MiniMax M3 | 179.4 | ~45 |
| DeepSeek V4 Pro | 85.6 | ~21 |
| DeepSeek V4 Pro Max | 75.3 | ~19 |
M3 at 179.4 char/s (~45 tok/s) is more than 2× faster than DeepSeek V4 Pro at 85.6 char/s (~21 tok/s). DeepSeek's lower speed reflects its heavier reasoning architecture (CSA+HCA with Muon optimizer). M3's MSA sparse attention appears to deliver faster inference — consistent with its architectural claims of 1/20th the per-token compute at long context.
Two Philosophies: The Generalist vs The Specialist
These models represent fundamentally different bets about what open-weight AI should be:
| Dimension | MiniMax M3 (The Generalist) | DeepSeek V4 Pro (The Specialist) |
|---|---|---|
| Bet | One model that does everything well | One model that does coding/math exceptionally well |
| Differentiator | Multimodality + 1M context + coding in one package | Algorithmic depth + MIT license + proven ecosystem |
| Ideal user | Full-stack devs who debug from screenshots and video | Backend/algorithm devs who need proven, cheap inference |
| Risk | Unverified benchmarks, unreleased weights, single provider | Text-only, slower inference, weaker on agentic benchmarks |
| Maturity | 3 days old (June 1, 2026) | 6 weeks old (April 23, 2026) |
Which Model for Which Task?
| Task | Better Model | Why |
|---|---|---|
| Production bug fixing (PRs, multi-file) | MiniMax M3 | 59.0% SWE-bench Pro — #3 overall behind only Opus |
| UI debugging from screenshots | MiniMax M3 | Native multimodal — DeepSeek is text-only |
| Computer use / desktop automation | MiniMax M3 | 70.0% OSWorld; DeepSeek has no published score |
| Web browsing agents | MiniMax M3 | 83.5% BrowseComp — edges Opus 4.7 |
| Speed-sensitive coding | MiniMax M3 | 179.4 char/s (~45 tok/s) — 2× faster on CodingFleet |
| Algorithmic / competitive programming | DeepSeek V4 Pro | 93.5% LiveCodeBench, 3206 Codeforces — M3 untested |
| Math-heavy reasoning | DeepSeek V4 Pro | 95.2% HMMT, 90.1% GPQA — M3 untested |
| Cost-sensitive volume (cached prompts) | DeepSeek V4 Pro | $0.0036/1M cached input — 16× cheaper than M3 |
| Self-hosting / air-gapped deployment | DeepSeek V4 Pro | MIT license, weights available NOW. M3 weights unreleased. |
| Production redundancy & multi-provider | DeepSeek V4 Pro | 14 providers; M3 has 1 |
The Bottom Line
- MiniMax M3 wins on benchmarks. DeepSeek V4 Pro wins on ecosystem and price. M3's 59.0% SWE-bench Pro is the best open-weight score available — #3 overall. But DeepSeek counters with 16× cheaper cached inference, MIT-licensed weights available today, 14 providers, and independent verification across every score.
- M3's multimodality is a genuine differentiator. Video input, image input, and computer use are capabilities DeepSeek doesn't offer. For UI development, design-to-code, and desktop automation, M3 is the only open-weight game in town.
- DeepSeek's algorithmic dominance is untouchable. 93.5% LiveCodeBench, 3206 Codeforces, 95.2% HMMT. M3 has no published scores on any algorithmic or math benchmark. If your work involves algorithms, DeepSeek is the clear choice among open-weight models.
- Trust but verify — M3's benchmarks are unconfirmed. All scores are vendor-reported. Weights haven't shipped. Independent verification is pending. DeepSeek has been independently benchmarked by Vals.ai, BenchLM, and the OpenRouter community for 6 weeks.
- Use both. M3 for production bug fixing, multimodal tasks, and speed. DeepSeek for algorithmic work, cached volume, and self-hosting. Both are open-weight. Both are 1-cost models on CodingFleet. Start a new chat → and route tasks between them based on what each does best.
📚 Related Articles
Sources: Lushbinary — MiniMax M3 Developer Guide | Vasundhara — M3 Explained | VentureBeat — M3 Launch | TechTimes — Unverified Benchmarks Warning | DeepSeek V4 Pro HF Model Card | BenchLM — M3 vs DS Comparison | OpenRouter — Comparison | CodingFleet Models — Speed Data. M3 scores vendor-reported; independent verification pending. DS scores independently verified.