
📊 Key Findings
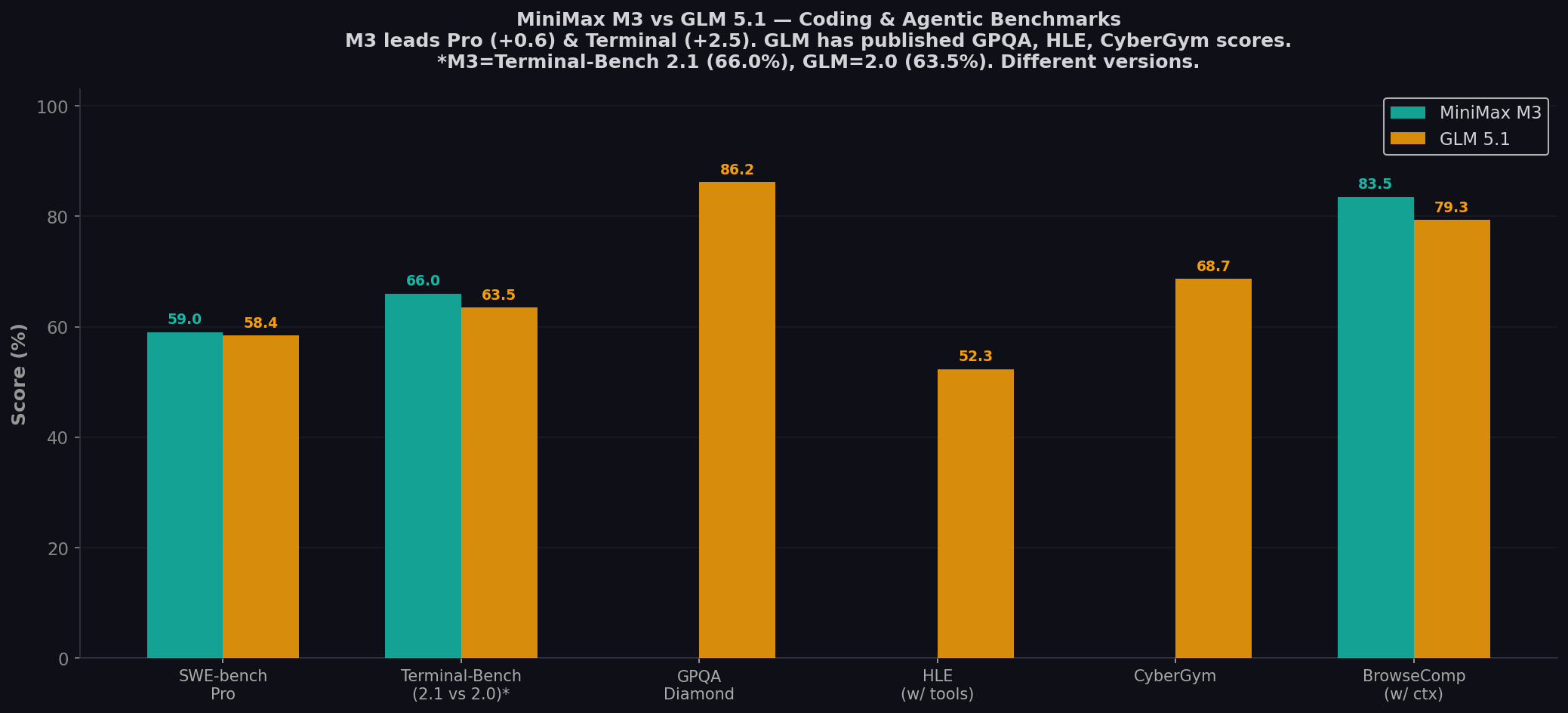
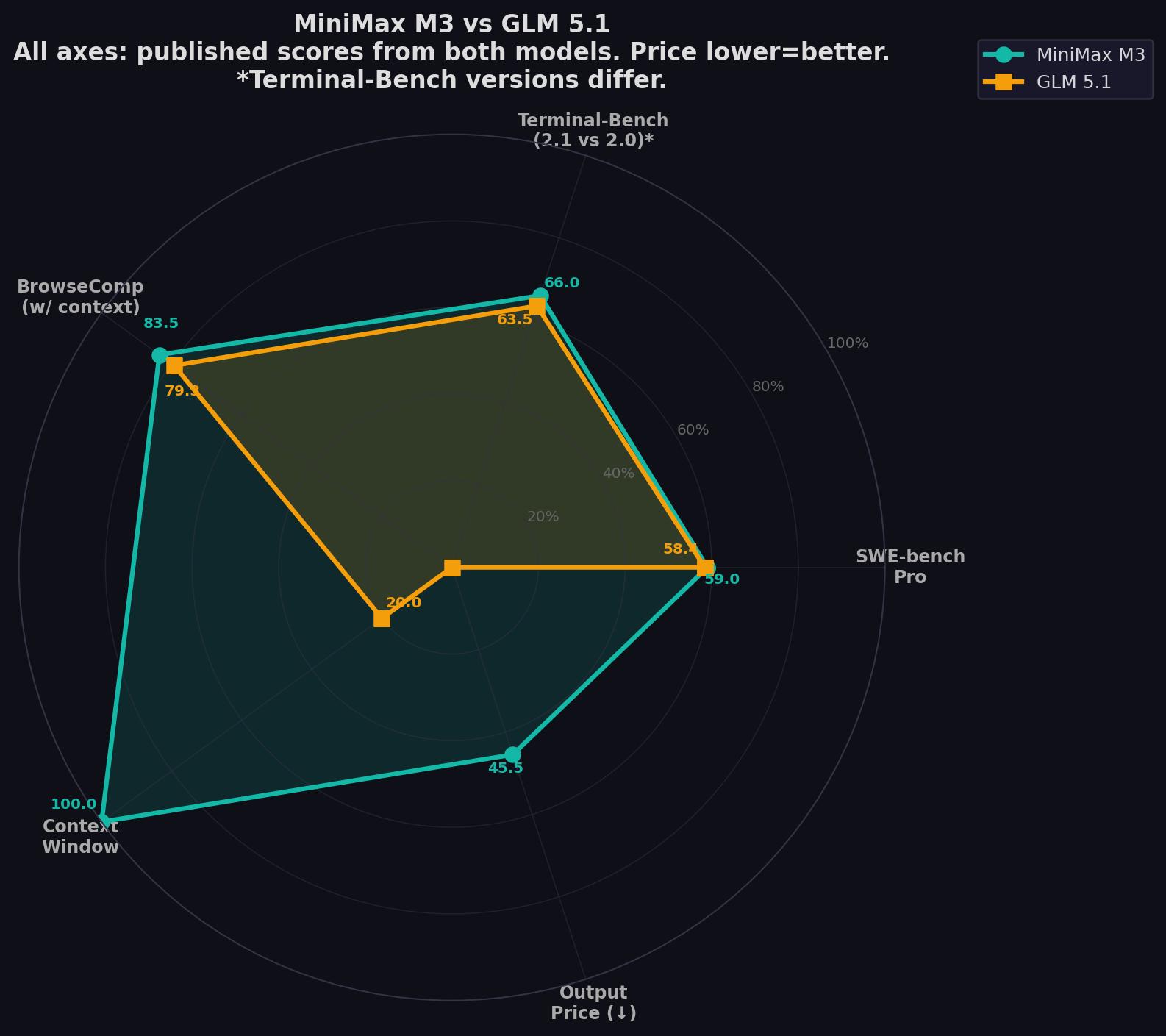
- 0.6 points apart on Pro: M3 59.0% vs GLM 58.4%. Within benchmark noise (+3.8–5.2 pp overestimation per ICSE 2026). These models are tied on coding.
- GLM dominates reasoning: 86.2% GPQA, 52.3% HLE w/tools, 68.7% CyberGym (#1 globally). M3 hasn't published GPQA/HLE scores.
- M3 has 5× context: 1M tokens vs GLM's 200K. Decisive for full-codebase analysis and multi-hour agent sessions.
- GLM has pure MIT license — unrestricted commercial use. M3 uses Modified MIT. Both open-weight, both self-hostable.
- Both trained on Huawei Ascend 910B — zero NVIDIA GPUs. Frontier AI no longer requires US silicon.
- M3 multimodal, GLM text-only: M3 handles image, video, desktop operation. GLM-5V Turbo handles vision separately.
Both models are available on CodingFleet. Start a new chat →
Benchmark Comparison
| Benchmark | MiniMax M3 | GLM 5.1 | Gap | Notes |
|---|---|---|---|---|
| SWE-bench Pro ★ | 59.0% | 58.4% | M3 +0.6 | Both vendor-reported. Gap within noise. Tied in practice. |
| SWE-bench Verified ⚠️ | 80.5% | 77.8% | M3 +2.7 | Contaminated per OpenAI Feb 2026. Historical only. |
| Terminal-Bench* | 66.0% | 63.5% | M3 +2.5 | *M3: 2.1, GLM: 2.0. GLM 69.0% with Claude Code harness. |
| GPQA Diamond | — | 86.2% | — | M3 not published. GLM solid but trails Opus 4.6 (91.3%). |
| HLE (w/ tools) | — | 52.3% | — | GLM ties GPT-5.5 (52.2%), beats Opus 4.6 (51.4%). |
| CyberGym | — | 68.7% | — | GLM #1 globally. Beats Opus 4.6 (66.6%). 1,507 tasks. |
| BrowseComp (w/ ctx) | 83.5 | 79.3 | M3 +4.2 | Autonomous browsing. M3 beats Opus 4.7 (79.3). |
| MCP Atlas | 74.2% | — | — | Tool orchestration. M3 published, GLM not. |
| OSWorld Verified | 70.0% | — | — | Computer use. M3 published, GLM not benchmarked. |
Sources: MiniMax M3 (Jun 1), Z.AI GLM-5.1 (Apr 7), Lushbinary, Serenities AI. Both vendor-reported. Terminal-Bench versions differ.
Benchmark Deep Dives
SWE-bench Pro: The 0.6-Point Phantom Lead
GLM 5.1 was the #1 open-weight model on Pro at launch (April 7), beating GPT-5.4 (57.7%) and Claude Opus 4.6 (57.3%). It held that crown 55 days until M3 took it by 0.6 points. In practice these models are tied — the ICSE 2026 study found SWE-bench overestimates by 3.8–5.2 pp, making a 0.6 gap meaningless.
Reasoning: GLM's Undisputed Lead
GLM at 86.2% GPQA, 52.3% HLE w/tools, and 68.7% CyberGym (#1 globally) was built for reasoning. The CyberGym #1 across 1,507 cybersecurity tasks is genuinely impressive. M3's silence on these benchmarks is the biggest unknown — until MiniMax publishes, GLM wins reasoning by default.
The Context Window: 5× Difference
M3's 1M-token context vs GLM's 200K is the biggest architectural difference. For full-codebase work, multi-file refactors, and long agent sessions, 1M tokens is transformative. GLM partially compensates with Claude Code compatibility and documented 8-hour autonomous sessions, but the raw capacity gap remains.
Architecture & Ecosystem
| Attribute | MiniMax M3 | GLM 5.1 |
|---|---|---|
| Release | June 1, 2026 (12 days) | April 7, 2026 (67 days) |
| Architecture | Sparse MoE + MSA | MoE — 754B total / 40B active |
| Context | 1M tokens | 200K tokens |
| Multimodal | Image + Video + Desktop | Text-only (GLM-5V Turbo for vision) |
| Training HW | Huawei Ascend 910B | Huawei Ascend 910B |
| License | Modified MIT | Pure MIT (unrestricted) |
| Weights | Promised within 10 days | Available now on HuggingFace |
| Ecosystem | MiniMax Code, Antigravity | vLLM, SGLang, Ollama, GGUF, $3/mo plan |
| AA Intel Index | — | 51 (#4/89 overall) |
Two Different Open-Weight Philosophies
GLM 5.1 is mature — weights on HuggingFace since April, supported by every major inference engine, documented deployment (4–8×H200), a $3/month Coding Plan. 67 days of community battle-testing. M3 is ambitious but unproven — 12 days old, weights promised, technical report pending. The community hasn't found its failure modes yet.
The Huawei Ascend Story
Both trained entirely on Huawei Ascend 910B — not a single NVIDIA GPU. US export controls were designed to prevent exactly this. GLM 5.1 proved it possible in April. M3 confirmed it in June. The gap between "NVIDIA-built" and "Ascend-built" has collapsed.
Pricing & Access
| Tier | MiniMax M3 | GLM 5.1 |
|---|---|---|
| Input/1M | $0.30 promo / $0.60 std | $1.40 |
| Output/1M | $1.20 promo / $2.40 std | $4.40 |
| Cache Hit | — | $0.26 (81% off) |
| Subscription | — | $3/month Coding Plan |
| Self-Hosted | Free + HW (TBD) | Free + 4–8×H200 |
| License | Modified MIT | Pure MIT |
💡 GLM's $3/month Coding Plan: The sleeper value proposition. $3/month for 58.4% SWE-bench Pro capability without per-token anxiety. No other model at this capability level offers a flat-rate subscription anywhere close to this price.
Which Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Bug fixing (Python) | M3 | Leads Pro + 5× context |
| Reasoning / STEM / security | GLM | 86.2% GPQA, 52.3% HLE, #1 CyberGym |
| Full-codebase analysis | M3 | 1M vs 200K context |
| Best value subscription | GLM | $3/month Coding Plan |
| Multimodal (video/images) | M3 | Native video + image + desktop |
| Commercial (max freedom) | GLM | Pure MIT, unrestricted |
| Deploy today | GLM | Weights on HF now |
| Agent loops / long sessions | M3 | 1M context for multi-hour runs |
The Bottom Line
These are the two most important open-weight models of 2026 — evenly matched in a way that makes the choice genuinely interesting. Pick M3 for context and multimodality. 1M tokens, video input, desktop operation. Pick GLM 5.1 for certainty and reasoning. Weights available now, pure MIT, proven over 67 days, $3/month. GLM 5.2 was announced but without benchmarks — GLM 5.1 remains the definitive GLM for comparison. The smartest approach: use both. Route reasoning to GLM, context-heavy tasks to M3.
🚀 Compare M3 and GLM 5.1 on Your Own Code
Both on CodingFleet. Test side-by-side on your stack.
Start a New Chat →Sources
- MiniMax M3 official blog (June 1, 2026)
- Z.AI GLM-5.1: Towards Long-Horizon Tasks (April 7, 2026)
- Lushbinary: GLM-5.1 Benchmarks Breakdown
- Serenities AI: GLM-5.1 Review
- MorphLLM: SWE-bench Pro Leaderboard
- Kilo Code: Best Open-Weight Coding Models
- BetterClaw: M3 vs GLM-5.1 vs Claude Cost Breakdown
- Artificial Analysis: GLM-5.1 Intel & Performance
- Z.AI: GLM 5.2 announcement (no benchmarks)