
For eleven days, Claude Opus 4.8 was the best AI model in the world. Released May 28, 2026, it dethroned GPT-5.5 on the Artificial Analysis Intelligence Index and led on coding benchmarks by wide margins. Then on June 9, Anthropic released Claude Fable 5 — its first publicly available Mythos-class model — and Opus 4.8 became the former king overnight. But the story isn't just "new model beats old model." Fable 5 represents a fundamental shift in Anthropic's philosophy: from calibrated, cautious honesty to raw, knowledge-driven power. And it costs twice as much. Here's the complete data-driven comparison — 30 benchmarks, pricing analysis, the honesty tradeoff, and when Opus 4.8 is still the smarter choice. Both models available on CodingFleet.
TL;DR: Claude Fable 5 leads on every published benchmark — SWE-bench Pro (+11.1), Terminal-Bench 2.1 (+5.3), AA-Omniscience (+12.7), GDPval-AA Elo (+42). But it costs 2× more ($10/$50 vs $5/$25 per 1M tokens) and represents a strategic shift: Fable 5 prioritizes raw accuracy (61% Omniscience) over calibrated honesty (hallucinates more than Opus 4.8's 35.9%). Fable 5 also includes safety classifiers that fall back to Opus 4.8 on ~5–9% of queries. For unattended coding agents where silent errors cost money, Opus 4.8's calibrated caution may still be safer.
Want to test both models side by side? Claude Fable 5 and Opus 4.8 are available on CodingFleet. Start a new chat → and compare them on your own code.
Release Context: 11 Days That Reshaped Anthropic's Lineup
| Detail | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Release Date | June 9, 2026 | May 28, 2026 |
| Model Class | Mythos (above Opus) | Opus (flagship) |
| Days as #1 | Current | 12 days (May 28 – June 9) |
| Predecessor | Claude Mythos 5 (restricted) | Claude Opus 4.7 (April 16) |
| AA Intelligence Index | 64.9 (#1) | 61.4 (#2) |
Artificial Analysis notes Fable 5's AA-Omniscience accuracy suggests it could be the largest public Anthropic model to date.
Opus 4.8 had the shortest reign of any Claude flagship. It brought Dynamic Workflows (hundreds of parallel subagents), a 4× honesty improvement, and the #1 Intelligence Index position. In any other month, it would have been the story of the summer. Instead, it became the bridge between the Opus era and the Mythos era.
Fable 5 is the same underlying model as Claude Mythos 5 — Anthropic's restricted model available only to US government partners through Project Glasswing. Fable 5 adds safety classifiers for cybersecurity, biology, chemistry, and distillation topics, routing flagged queries to Opus 4.8. Anthropic says this fallback occurs in fewer than 5% of sessions; Artificial Analysis measured it at ~8–9% across their benchmark suite.
Head-to-Head Benchmark Comparison
Below is the most comprehensive side-by-side comparison available as of June 11, 2026. Purple cells indicate the leader. "—" means no published score.
Agentic Coding Benchmarks
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| SWE-bench Verified | 95.0% (Vals.ai); 93.9% (Anthropic) | 88.6% | Fable 5 (+6.4) |
| SWE-bench Pro | 80.3% | 69.2% | Fable 5 (+11.1) |
| SWE-bench Multilingual | ~87% | 84.4% | Fable 5 (~+2.6) |
| Terminal-Bench 2.1 | 88.0% | 82.7% | Fable 5 (+5.3) |
| FrontierCode Diamond | 29.3% | 13.4% | Fable 5 (+15.9) |
| CursorBench 3.1 | 72.9% | — | Fable 5 |
Browser, Tools & Computer Use
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| OSWorld-Verified | 85.0% | 83.4% | Fable 5 (+1.6) |
| MCP Atlas | — | 82.2% | Opus 4.8 (only score) |
| Online-Mind2Web | — | 84% | Opus 4.8 (only score) |
| BrowseComp (multi-agent) | — | 88.5% | Opus 4.8 (only score) |
| Toolathlon | — | 59.9% | Opus 4.8 (only score) |
Knowledge Work & Professional Benchmarks
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| GDPval-AA (Elo) | 1932 | 1890 | Fable 5 (+42) |
| GDP.pdf (no tools) | 29.8% | 22.5% | Fable 5 (+7.3) |
| Finance Agent v2 | 56.3% | 53.9% | Fable 5 (+2.4) |
| AutomationBench | 17.4% | 15.5% | Fable 5 (+1.9) |
| HealthBench Professional | 66.0% | 56.9% | Fable 5 (+9.1) |
Reasoning & Academic
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| GPQA Diamond | ~93% (estimated, tied) | 93.6% | Tie |
| HLE (no tools) | 59.0% | 49.8% | Fable 5 (+9.2) |
| HLE (with tools) | 64.5% | 57.9% | Fable 5 (+6.6) |
| Blueprint-Bench 2 (spatial reasoning) | 38.6% | 14.5% | Fable 5 (+24.1) |
| USAMO 2026 | — | 96.7% | Opus 4.8 (only score) |
| ARC-AGI-2 (High) | — | 72.1% | Opus 4.8 (only score) |
Intelligence & Honesty
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| AA Intelligence Index | 64.9 (#1) | 61.4 (#2) | Fable 5 (+3.5) |
| AA-Omniscience Index | 40.0 (#1) | 27.4 (#3) | Fable 5 (+12.6) |
| AA-Omniscience Accuracy | 61.0% (#1) | 46.6% | Fable 5 (+14.4pp) |
| AA-Omniscience Hallucination | Higher than 35.9%* | 35.9% | Opus 4.8 (more honest) |
| GraphWalks BFS 1M | 80.0% | 68.1% | Fable 5 (+11.9) |
| Legal Agent Benchmark | 13.3% | 10.4% | Fable 5 (+2.9) |
Biology & Health
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| BioMysteryBench (hard) | 46.1% | 40.0% | Fable 5 (+6.1) |
| BioMysteryBench (human solved) | 83.9% | 80.4% | Fable 5 (+3.5) |
*AA states Fable 5's Omniscience is "driven by leading accuracy, rather than low hallucinations." Exact Fable 5 hallucination rate unpublished. Fallback to Opus 4.8 on 9% of Omniscience questions.
Cybersecurity
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| ExploitBench | 78.0% (Mythos 5; Fable 5 falls back on cyber) | 40.0% | Fable 5 (+38.0)* |
| CyberGym | — (falls back to Opus 4.8) | 78.8% | Opus 4.8 (effective) |
*Fable 5's safety classifiers reroute cybersecurity queries to Opus 4.8 — effective performance is closer to Opus 4.8 levels for most users.
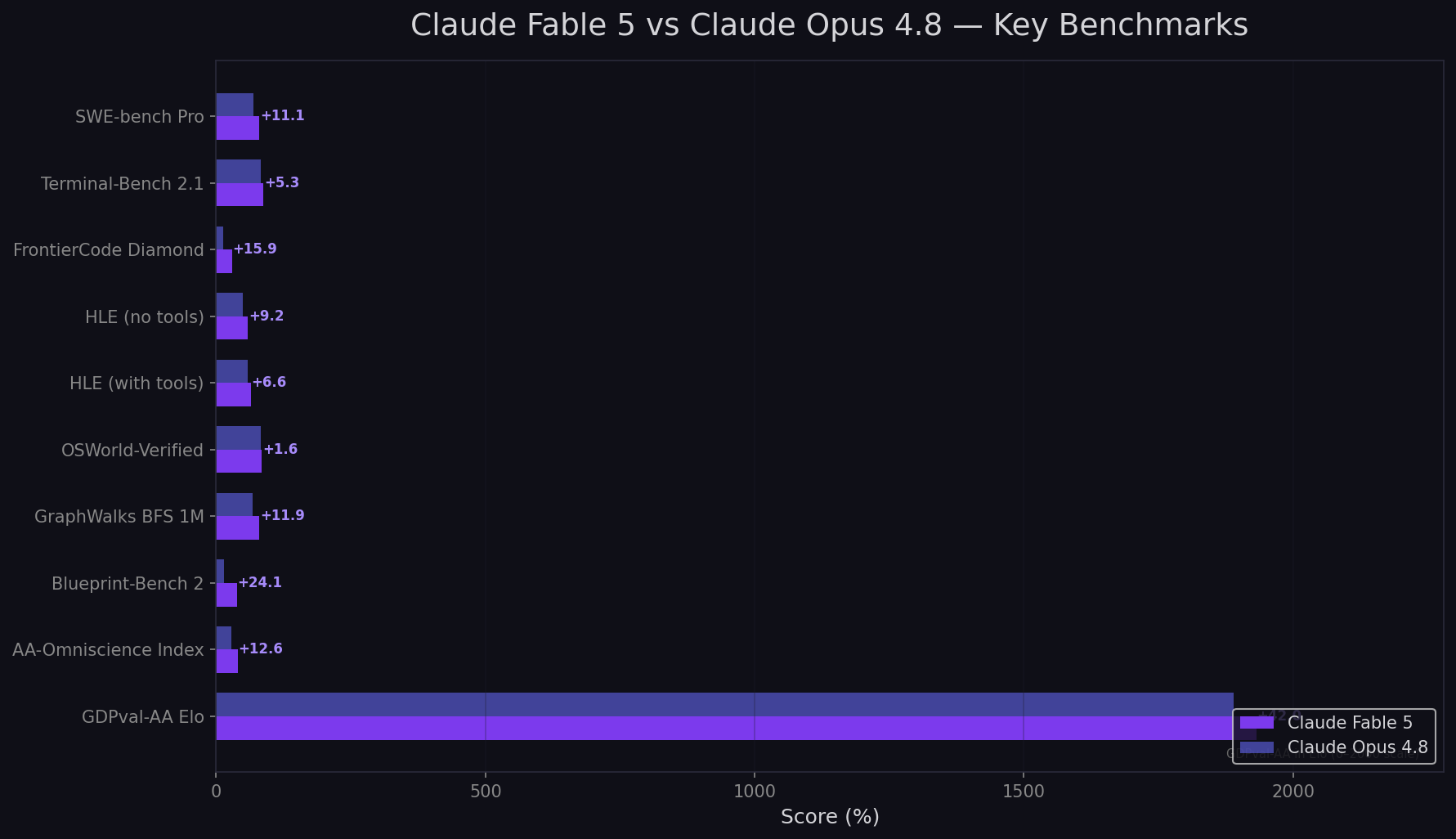
What Each Benchmark Actually Means
SWE-bench Pro — The 11.1-Point Leap
SWE-bench Pro tests real GitHub issue resolution: reading codebases, making multi-file changes, passing test suites. Fable 5's 80.3% vs Opus 4.8's 69.2% is an 11.1-point gap — larger than Opus 4.8's lead over GPT-5.5 (10.6 points). On SWE-bench Verified, Fable 5 hits 95.0% per Vals.ai independent testing — approaching the benchmark ceiling. The gap widens on harder tasks: Fable 5 scores 93%+ on 1–4 hour tasks while competing models drop sharply.
FrontierCode Diamond — The 15.9-Point Explosion
FrontierCode Diamond tests production-quality code for complex, novel problems. Fable 5: 29.3%. Opus 4.8: 13.4%. GPT-5.5: 5.7%. This is the largest gap on any shared benchmark. Fable 5 more than doubles Opus 4.8's score on original problem decomposition — the kind of coding that has no Stack Overflow answer.
Terminal-Bench — The CLI Takeover
Fable 5: 88.0%. Opus 4.8: 82.7%. A 5.3-point gap. Fable 5 is now the #1 model on Terminal-Bench 2.1, dethroning GPT-5.5 (83.4%). For DevOps automation and CLI agent coding, Fable 5 is the best model from any provider.
AA-Omniscience — The Honesty Tradeoff
This is where the comparison gets philosophically interesting. Fable 5 scores 40 (#1). Opus 4.8 scores 27.4 (#3). But the drivers are completely different:
- Fable 5: 61% accuracy (highest ever) — it knows more than any model. But hallucinates more than Opus 4.8. When Fable 5 doesn't know, it's more likely to fabricate.
- Opus 4.8: 46.6% accuracy — knows less. But 35.9% hallucination rate — when it doesn't know, it stays quiet.
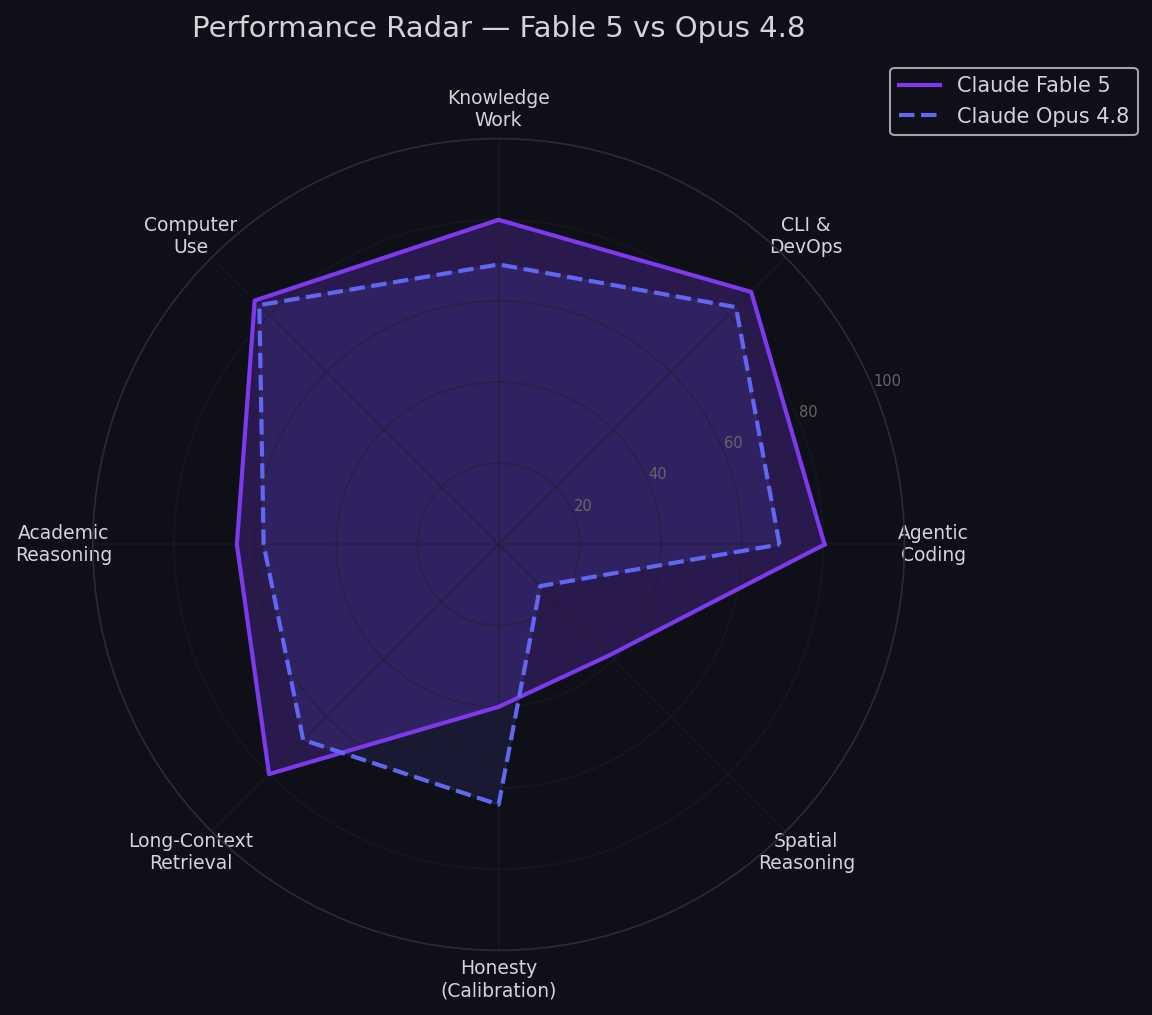
Fable 5 knows more but lies more. Opus 4.8 knows less but is more calibrated about its uncertainty. For unattended agents where silent errors cost money, Opus 4.8 is safer. For research where you'll verify output, Fable 5 is transformative.
GraphWalks — Long-Context Retrieval
Fable 5: 80.0% at BFS 1M. Opus 4.8: 68.1%. An 11.9-point gap. For reasoning over entire codebases, Fable 5 retrieves significantly more reliably at the upper end of the context window.
HLE — Fable 5 Takes the Lead
Fable 5: 59.0% (no tools), 64.5% (with tools). Opus 4.8: 49.8%, 57.9%. Gaps of 9.2 and 6.6 points respectively. Fable 5 leads decisively on Humanity's Last Exam — the hardest academic benchmark. Note: Artificial Analysis independently measured Fable 5 at 53.0% with tools, lower than Anthropic's 64.5% — the difference is that AA's measurement includes the 9% of HLE tasks where Fable 5's safety classifiers triggered fallback to Opus 4.8. Anthropic's system card score represents Fable 5's native capability without fallback.
Blueprint-Bench 2 — The 24.1-Point Spatial Explosion
Fable 5: 38.6%. Opus 4.8: 14.5%. This is the largest relative gap on any benchmark — a 24.1-point difference. Blueprint-Bench 2 tests spatial reasoning: understanding blueprints, floor plans, and 3D spatial relationships. Fable 5 nearly triples Opus 4.8's score. Anthropic reports this represents a "nearly 3× improvement" in spatial reasoning over Opus 4.8. For architecture, engineering, and any domain requiring spatial intelligence, Fable 5 is in a different league.
Legal Agent Benchmark — Both Break 10%
Opus 4.8 was the first model to break 10% on this benchmark (10.4%). Fable 5 extends the lead to 13.3% — a 2.9-point gain. Both models far outpace GPT-5.5 (2.1%) and Gemini 3.1 Pro (0.0%). For legal coding and compliance workflows, either Claude model is the clear choice — but Fable 5 is measurably better.
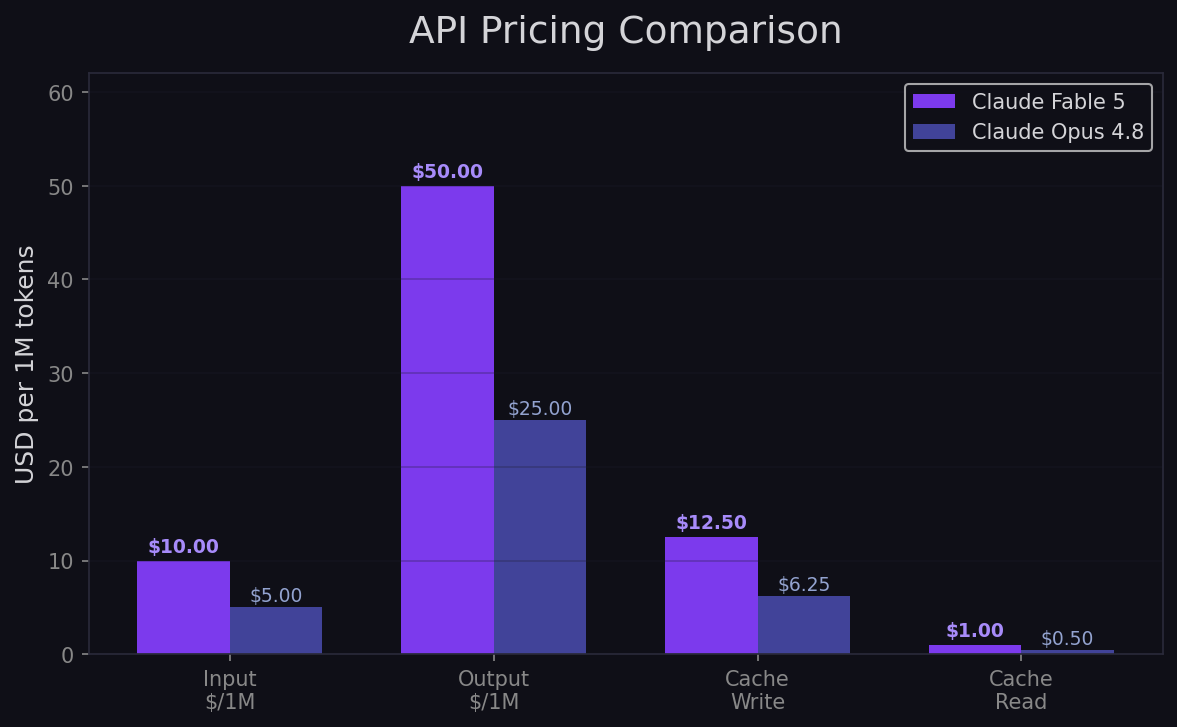
Pricing: The 2× Decision
| Detail | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Input (per 1M tokens) | $10.00 | $5.00 |
| Output (per 1M tokens) | $50.00 | $25.00 |
| Cache write (per 1M tokens) | $12.50 | $6.25 |
| Cache read (per 1M tokens) | $1.00 | $0.50 |
| Context window | 1M input | 1M input / 128K output |
| Batch/Flex discount | ✅ 50% off | ✅ 50% off |
| Subscription access | Included until June 22, then credits | Included in all paid plans |
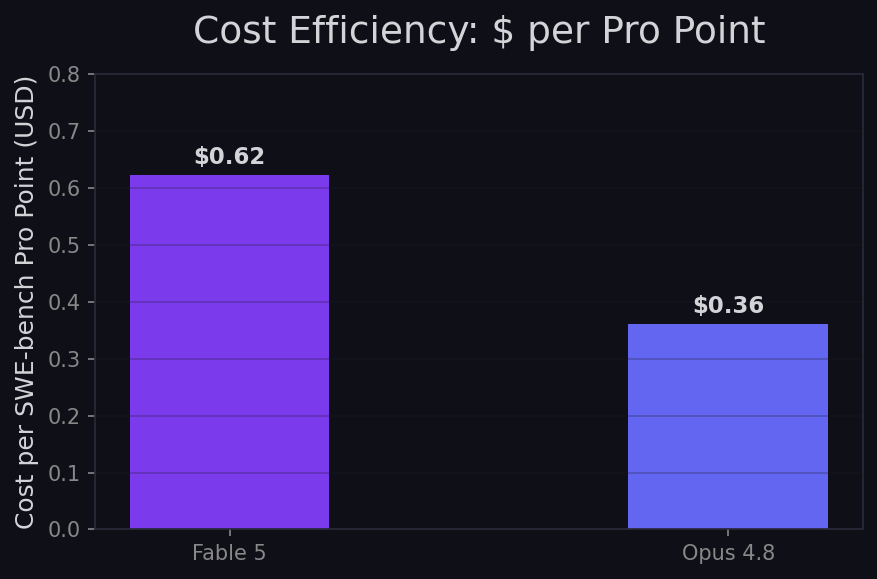
Cost per SWE-bench Pro point: Fable 5: $0.62/point. Opus 4.8: $0.36/point. Fable 5 gives you 16% more Pro performance for 100% more cost. For teams fixing production bugs where an incorrect fix costs thousands, the premium is trivial. For high-volume generation, Opus 4.8 is better value.
The Safety Architecture: Fable 5's Hidden Opus 4.8
Fable 5's most unusual feature is invisible to most users. Safety classifiers automatically reroute queries on cybersecurity, biology, chemistry, and AI distillation topics to Opus 4.8. When this happens, latency and cost profiles change mid-request. Users report classifiers being "trigger-happy" — a medical physicist wrote: "I genuinely can't use Fable. I'm a medical physicist. I use the word nuclear a lot." If your work touches these domains, using Opus 4.8 directly may be more predictable — and cheaper.
Unique Features: What Each Model Brings
Fable 5 Advantages
- Mythos-class intelligence: Largest public Anthropic model. Highest accuracy on AA-Omniscience (61%).
- Token efficiency on complex tasks: Frontier physics research requires 3× fewer tokens vs GPT-5.5.
- Stripe's 50M-line migration in a day: Estimated at 2+ months for a human team.
- #1 on Terminal-Bench, SWE-bench Pro, FrontierCode Diamond, AA-Omniscience, GraphWalks.
Opus 4.8 Advantages
- 35.9% hallucination rate: Best calibration of any flagship. When it doesn't know, it says so.
- Dynamic Workflows in Claude Code: Hundreds of parallel subagents with adversarial verification.
- Fast Mode: 2.5× speed at $10/$50. Fable 5 has no Fast mode equivalent.
- 96.7% USAMO 2026: Highest published math score of any model.
- No safety fallbacks: You always get Opus 4.8 — not a downgraded model on certain topics.
- Stable subscription access: Included in all plans with no credit expiration looming.
- Half the cost: $5/$25 vs $10/$50 per 1M tokens. Better value for high-volume use.
Which Model Should You Use?
| Use Case | Better Model | Why |
|---|---|---|
| Complex bug fixing (multi-file, 4+ files) | Fable 5 | 80.3% Pro vs 69.2%. Gap widens on harder tasks. |
| CLI / DevOps automation | Fable 5 | 88.0% Terminal-Bench. #1 overall. |
| Codebase-scale migrations | Fable 5 | FrontierCode 29.3%. Stripe 50M-line proof. |
| Knowledge work (research, finance, legal) | Fable 5 | 1932 GDPval-AA. 61% accuracy. 74% win rate vs Opus. |
| Long-context reasoning (500K–1M) | Fable 5 | 80.0% GraphWalks vs 68.1%. |
| Computer-use / browser agents | Fable 5 | 85.0% OSWorld vs 83.4%. |
| Unattended agents (no human review) | Opus 4.8 | 35.9% hallucination. Won't silently ship broken code. |
| Scientific / academic reasoning | Fable 5 | 59.0% HLE (no tools) vs 49.8%. 64.5% with tools. Fable leads decisively. |
| Cybersecurity work | Opus 4.8 | Fable 5 reroutes cyber queries to Opus 4.8 anyway. |
| Cost-sensitive high-volume production | Opus 4.8 | $25 vs $50/1M output. 2× cheaper. |
| Biology / chemistry / medical research | Opus 4.8 | Fable 5 classifiers flag these domains. Despite higher BioMysteryBench scores, fallback risk makes Opus more predictable. |
| Math competition / theorem proving | Opus 4.8 | 96.7% USAMO. Fable 5 score not published. |
Conclusion: Two Kings, Different Thrones
Claude Fable 5 is the most capable AI model Anthropic has ever made publicly available. The 11.1-point SWE-bench Pro gap, the 15.9-point FrontierCode gap, and the 12.6-point AA-Omniscience gap are generational — not marginal. For complex engineering work, codebase migrations, CLI automation, and knowledge-heavy tasks, Fable 5 is unmatched.
But calling it a pure upgrade misses the point. These two models represent different philosophies within the same company:
- Fable 5 bets on raw capability — it knows more, codes better, reasons deeper. But hallucinates more, costs 2× more, and sometimes silently downgrades to Opus 4.8.
- Opus 4.8 bets on calibrated trust — it knows less but lies less (35.9% hallucination). Costs half. Has no safety fallbacks. Holds the published math crown (96.7% USAMO). Better for unattended agents and cost-sensitive pipelines.
For most developers, the practical answer is both. Use Fable 5 for complex engineering where you'll verify output. Use Opus 4.8 for unattended agents, cost-sensitive pipelines, scientific work, and cybersecurity. Both are available side by side on CodingFleet — you don't have to choose one forever.
And if you can only pick one? Fable 5 is the better model by every benchmark. But the question isn't just "which is better." It's "which is better for your specific work — and which tradeoffs can you live with?" For the first time, Anthropic is asking users to make that call between two very different versions of excellence.
Both models available. Side-by-side testing on your own code.
📚 Related Articles
Sources: Anthropic — Fable 5 & Mythos 5 System Card | Anthropic — Opus 4.8 System Card | Artificial Analysis — Fable 5 Intelligence Index | AA-Omniscience Leaderboard | Vals.ai — SWE-bench Verified | Vellum — Opus 4.8 Benchmarks | Finout — Fable 5 Pricing. All benchmark scores vendor-reported unless otherwise noted. Pricing as of June 11, 2026.